Moduldeklaration
Module im CODESYS Application Composer werden über eine Moduldeklaration beschrieben. Die Moduldeklaration ist ein eigenes Objekt im POU‑Pool und bildet die Grundlage für die Verwendung eines Moduls im Modulbaum.
Objekte im POU:
Die Deklaration von Modulen erfolgt über eine eigene Beschreibungssprache, die an die Deklaration von Variablen im ST‑Code (Structured Text) angelehnt ist.
Jede Moduldeklaration basiert auf einem Funktionsbaustein (Modul‑FB)
Der Modul‑FB enthält die funktionale Logik
Die Moduldeklaration ergänzt den Modul‑FB um Konfigurations‑ und Strukturinformationen
Parameter
Eingangsvariablen des Modul‑FBs können als Parameter gekennzeichnet werden, um eine strukturierte Parametrierung des Moduls zu ermöglichen.
Modul‑Ein- und Ausgänge
Ein- und Ausgangsvariablen des Modul‑FBs können als Modul‑E/As definiert und mit Variablen, anderen Modulen oder Geräte‑E/As verbunden werden.
Slots
Slots ermöglichen die Einbindung anderer Module als Sub‑Module und definieren damit eine hierarchische Modulstruktur.
Default‑Submodule
Vordefinierte Belegungen für Modul‑Slots, die beim Einfügen eines Moduls automatisch angewendet werden.
Visualisierungen
Module können Seiten‑Visualisierungen sowie eingebettete Visualisierungen bereitstellen, die automatisch erzeugt und verknüpft werden.
Proxy‑Modul‑FBs
Zur Realisierung von Referenzen über Applikations‑ oder Steuerungsgrenzen hinweg können Proxy‑Funktionsbausteine definiert werden.
Instanz‑Referenzen
Referenzen auf FB‑Instanzen, die erst zur Konfigurationszeit durch den Anwender auf konkrete Instanzen abgebildet werden.
Alarme
Module können das CODESYS Alarm‑Management nutzen, um Alarme für Variablen des Modul‑FBs zu definieren und auszuwerten.
Ablauf‑Kennzeichnungen
Kennzeichnungen zur Verwendung von Modulen in sequenziellen Abläufen, z. B. in Schrittketten.
Format der Moduldeklaration
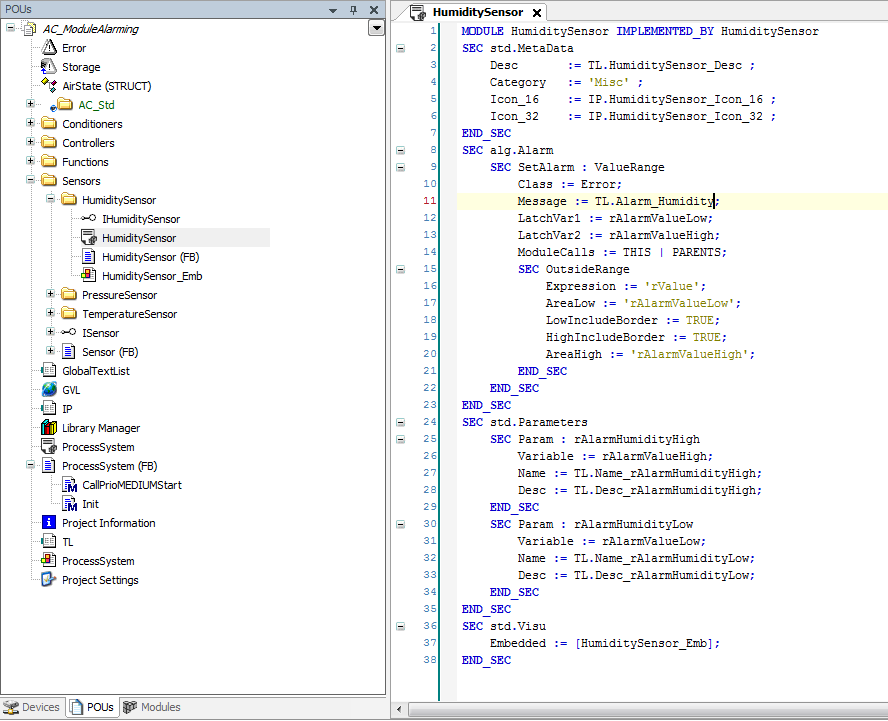
Ein Header der Form MODULE <Name> leitet die Deklaration ein. Es folgt eine Liste von sogenannten Abschnitten.
Jeder Abschnitt wird durch das Schlüsselwort SEC (für „Section“) eingeleitet und hat einen eindeutigen Namen. Ein Abschnitt wird mit dem Schlüsselwort END_SEC abgeschlossen. Der Inhalt eines Abschnitts ist eine Liste von Einträgen, die entweder wiederum Abschnitte oder aber sogenannte Definitionen sein können.
Eine Definition besteht aus einem Namen und einem (optionalen) Wert und wird mit einem Semikolon abgeschlossen.
Kommentare können wie in ST verwendet werden: „//“ für einzeilige Kommentare und „(*“ and „*)“ für mehrzeilige Kommentare, die auch verschachtelt sein dürfen. Whitespace (Tabulatoren und Leerzeichen) und Newline/Linefeed-Zeichen spielen nur insofern eine Rolle, als sie die einzelnen Bestandteile einer Deklaration trennen. Ansonsten werden sie bei der weiteren Bearbeitung ignoriert.
Groß- und Kleinschreibung spielt, wie bei ST, keine Rolle.
01 MODULE Persistence IMPLEMENTED_BY PersistenceFB 02 SEC MetaData 03 NAME := TL.ChannelName ; 04 DESC := TL.ChannelDesc ; 05 COLLECTION CATEGORY := ’Persistence’TL.Collection ; 06 ICON_16 := IP.Channel16 ; 07 ICON_32 := IP.Channel32 ; 08 END_SEC 09 SEC Toplevel 10 SEC STANDARD_TASK : LOW 11 NAME := LOW ; 12 DESC := TL.TaskLow ; 13 FLAGS := CREATE_IF_MISSING | READONLY ; 14 END_SEC 15 GVL_NAME := 'GVL_%InstanceName%' ; 16 END_SEC
In Zeile 01 wird der Modulname festgelegt. Außerdem wird mit IMPLEMENTED_BY der Name des Funktionsbaustein festgelegt, der die Logik des Moduls definiert. Dieser Funktionsbaustein muss von IModule ableiten. In Zeile 02 beginnt der Abschnitt MetaData, der in Zeile 08 endet. Dieser Abschnitt enthält fünf Definitionen. Die Möglichkeit von verschachtelten Abschnitten demonstriert der Abschnitt Toplevel (Zeile 09 – 16), der einen Abschnitt STANDARD_TASK (Zeile 10) enthält.
Syntax der Moduldeklaration
In diesem Abschnitt werden die Syntax und die zulässige syntaktische Struktur einer Moduldeklaration erklärt.
Im Folgenden werden Scanner-Token in Großbuchstaben gesetzt (beispielsweise ID). Nichtterminale der Grammatik werden in geschweifte Klammern gesetzt (beispielsweise {Entry}).
Lexikalische Analyse (Scanner)
In der ersten Phase werden aus den einzelnen Zeichen der Moduldeklaration sogenannte Token (oder Lexeme) gebildet, zum Beispiel Schlüsselwörter, Konstanten, Identifier.
Whitespace sowie Newline/Linefeed-Zeichen trennen Token, werden aber ansonsten ignoriert. Kommentare werden für die weitere Verarbeitung der Deklaration ebenfalls ignoriert. (Kommentare können, wie oben schon gesagt, wie in ST als einzeilige (//“) oder mehrzeilige Kommentare ((* und *)) auftreten, letztere auch verschachtelt.)
Grundsätzlich gilt die Regel, dass ein Token immer die maximal mögliche Länge hat. Zum Beispiel wird a123 als ein Identifier und nicht als Identifier a gefolgt von einem Literal 123 eingelesen.
Außerdem gibt die Reihenfolge, in der die Token unten beschrieben sind, ihre Priorität vor. Die Eingabe MODULE wird beispielsweise als Schlüsselwort erkannt und nicht als Identifier.
Schlüsselwörter:
MODULE,SEC,END_SEC,IMPORTS,IMPLEMENTED_BYOP: eine nichtleere Sequenz der folgenden Zeichen:
.:,%()[]{}<>|+-*/@!?^°=\~Anmerkung: Die Kommentarmarkierungen
//,(*und*)haben höhere Priorität als Operatoren. Andererseits kann innerhalb eines Operators kein Kommentar beginnen, beispielsweise wird+//+, gemäß der Regel maximaler Länge, als Operator eingelesen und nicht als+gefolgt von einem Kommentar.LIT: ein IEC-Literal, wie es auch in ST verwendet werden darf, beispielsweise
1.4,tod#12:13:14. Hierzu zählen auch die booleschen LiteraleTRUEundFALSE(unabhängig von der Groß-/Kleinschreibung).Anmerkung: Ungetypte Literale mit vorangestelltem negativen Vorzeichen (
-1,-3.2) werden als zwei Token eingelesen, nämlich als Operator-gefolgt von einem ungetypten Literal. Es folgt, dass ungetypte numerische Literale nie negativ sind. Getypte Literale (INT#-34) werden aber immer als ein Token eingelesen.ID: ein gültiger IEC-Identifier (
[a-zA-Z_][a-zA-Z0-9_]*), wobei zwei aufeinanderfolgende Unterstriche nicht erlaubt sind. Hierzu zählen, anders als in ST, auch die Schlüsselwörter von ST (beispielsweiseFUNCTION,INT,EXTENDS, …)SEMICOLON: das Zeichen
;
Syntax (parser)
Die Syntax der Moduldeklaration wird durch folgende Grammatik definiert. µ ist die leere Sequenz.
{MDecl} ::= MODULE {QID} {ImplSpec} {ImportsSpec} {MBody}
{ImplSpec} ::= IMPLEMENTED_BY {QID} | µ
{ImportsSpec} ::= IMPORTS {QID} | µ
{MBody} ::= {SecList}
{SecList} ::= {Modifiers} {Sec} {SecList} | µ
{Sec} ::= SEC {QID} {SecTarget} {EntryList} END_SEC
{SecTarget} ::= OP(":") {QID} | µ
{Modifiers} ::= OP("[") {ModifierList} OP("]") | µ
{ModifierList} ::= {QID} OP(",") {ModifierList} | {QID}
{EntryList} ::= {Modifiers} {Entry} {EntryList}
{Entry} ::= {Sec} | {Def}
{Def} ::= {QID} OP(":=") {ValList} SEMICOLON |
{QID} SEMICOLON
{ValList} ::= {Val} {ValList} | {Val}
{Val} ::= ID | LIT | OP
{QID} ::= ID | ID OP(".") {QID}Die Liste der Werte einer Definition ({ValList}) muss mit einem Semikolon abgeschlossen werden. Dies vereinfacht die Grammatik und verhindert Mehrdeutigkeiten, da das Semikolon innerhalb eines Wertes ({VAL}) nicht vorkommen kann (außer innerhalb eines String-Literals).
Ebenso dient der Zuweisungsoperator (:=) bei Definitionen ({Def}) dazu, Mehrdeutigkeiten zwischen dem Namen der Definition ({QID}) und den Werten zu vermeiden.
Definierte Typen für Definitionen
Text: ID.ID (Textlistenname und Textlisten-Identifier) - siehe Lokalisierung von Strings in Textlisten
Image: ID.ID (Name und ID der Bildersammlung)
ID (IEC Identifier)
QID (Qualified identifier):
{QID} ::= ID | ID.IDCategoryPath ::= {StringLiteral} | {CategoryPath}Cardinality:
[{MIN} .. {MAX}]|[ {MIN} .. INF [{MIN}und{MAX}sind ganzzahlige, nichtnegative Literale. Falls{MAX} != INFmuss{MIN} <= {MAX}gelten.StringLiteral: Ein IEC-String Literal darf Zeilenumbrüche enthalten.
StdTaskFlags ::= {StdTaskFlag} | {StdTaskFlags} StdTaskFlag ::=
NONE|CREATE_IF_MISSING|READONLYLiteral:beliebiges IEC-Literal oder QID (für Enum-Konstanten)
DTBoolFlag:
µ(leere Sequenz) |TRUE|FALSESlotType:
SUBMODULE|REFERENCEPragmas:
[ {PragmaList} ] {PragmaList} ::= {Pragma}|{Pragma} , {PragmaList} {Pragma} ::= { ( ID|{StringLiteral}|{OP2} )+ } {OP2}: Jeder Operator außer{, }, [, ]und,.InstancePath:
InstancePath ::= {IComp}|{IComp} . {IComp}mit{IComp} ::= ID {ArrayAccess}*und{ArrayAccess} ::= [ {IntList} ]und{IntList} ::= Int|Int , {IntList}TaskRef: Standard_Task. (
Low|Medium|High) |Custom_Task.ID
Instanzpfade
An einigen Stellen der Moduldeklaration können Instanzpfade angegeben werden, die eine Variable des Module-Funktionsbausteins adressieren: Bei Parametern, Slots, E/As, Arrays konfigurierbarer Größe und bei Instanzreferenzen.
Ein Instanzpfad besteht aus einer nichtleeren, durch Punkte getrennten Folge von Komponenten: C1.C2…CN. Eine Komponente ist entweder ein IEC-Bezeichner oder eine Komponente gefolgt von einem Index-Ausdruck [i1, …, iN] wobei i1 bis iN ganzzahlige Literale sind.
Instanzpfade sind immer relativ zum Funktionsbaustein, der die Modullogik implementiert. Die erste Komponente des Instanzpfads ist ein Member (VAR_INPUT oder VAR_OUTPUT, je nach Anwendungsfall) des Funktionsbausteins. Hat der Instanzpfad weitere Komponenten, dann adressieren diese die Variable innerhalb des Members. Ansonsten ist das Member selbst adressiert. Instanzpfade können auf Eingangs- oder Ausgangsvariablen eingeschränkt werden (zum Beispiel bei I/Os). Für Strukturen gelten diese Einschränkungen nicht. Solche Instanzpfade werden als Eingangs-Instanzpfad bzw. Ausgangs-Instanzpfad bezeichnet
Lokalisierung von Strings in Textlisten
Texte, die lokalisiert werden sollen (beispielsweise Beschreibungen von Modulen, Name, Beschreibung von Parametern), werden in Textlisten verwaltet.
Der Name der Sprache hat das Format
<LanguageCode>[-<Country/Region>](beispielsweiseen-US,de-DE).<LanguageCode>ist der Name der Sprache nach ISO 639-1 (beispielsweisedeoderen).<Country/Region>ist ein Regional-Code nach ISO 3166Beim Nachschlagen eines Textlisteneintrags wird zunächst nach dem vollen Sprachnamen gesucht und wenn dieser nicht gefunden wird nach dem
<LanguageCode>gesucht. Wird auch dieser nicht gefunden, so wird der Default-Text verwendet.
Sprache | Name der Sprache |
|---|---|
Chinesisch | zh-CHS |
Englisch | en-US |
Französisch | fr-FR |
Deutsch | de-DE |
Italienisch | it-IT |
Japanisch | ja-JP |
Portugisisch | pt-PT |
Russisch | ru-RU |
Spanisch | es-ES |
Ableiten von Moduldeklarationen
Analog zum objektorientierten Ableiten eines Funktionsbausteins A von einem Funktionsbaustein B („EXTENDS“) ist auch das Ableiten von Moduldeklarationen über IMPORTS möglich. Die beiden Modifier UPDATE und HIDE werden gesondert behandelt.
Der Name des importierten Moduls muss mit Namensraum qualifiziert sein, wenn dieses Modul in einer anderen Bibliothek definiert ist.
Es darf keine zyklischen Ableitungen geben, insbesondere darf ein Modul nicht von sich selbst ableiten. (Eine zyklische Ableitung ist eine Ableitungskette der Form Modul M_1 leitet von Modul M_2 ab, M_2 von M_3, …, M_N wieder von M_1.)
Ein abgeleitetes Modul kann die
IMPLEMENTED_BY-Direktive weglassen. In diesem Fall wird der Funktionsbaustein des Basismoduls verwendet.Falls ein abgeleitetes Modul über
IMPLEMENTED_BYeinen Funktionsbaustein angibt, dann muss dieser entweder vom Funktionsbaustein des Basismoduls ableiten oder identisch mit diesem sein .Ein abgeleitetes Modul übernimmt alle Abschnitte vom Basismodul. Es kann neue Abschnitte hinzufügen oder bestehende verändern.
Ein Abschnitt wird verändert, indem er mit demselben Namen und Target und dem Modifier
UPDATEim abgeleiteten Modul deklariert wird. In diesem Fall können seine Einträge verändert werden. Alle nicht aufgeführten Einträge des Abschnitts werden aus dem Basismodul übernommenDie Modifier
UPDATEundHIDEdürfen nur verwendet werden, wenn der entsprechende Abschnitt (Name und Target) im Basismodul definiert ist. Umgekehrt darf ein Abschnitt, der im Basismodul vorkommt, nur dann im abgeleiteten Modul aufgeführt werden, wenn er mitUPDATEoderHIDEversehen ist. Wenn ein Abschnitt nur mitHIDEund nicht mitUPDATEversehen ist, darf er keine Einträge haben.Bestimmte Einträge müssen in einem abgeleiteten Modul geändert werden (beispielsweise der Name und die Beschreibung.)
MODULE MBase IMPLEMENTED_BY FBBase
SEC MetaData
DESC := TL.Desc_Base ;
END_SEC
SEC Parameters
SEC Param : paramxIn
Variable := xIn ;
Name := TL.Param1_Name ;
Desc := TL.Param1_Desc ;
END_SEC
END_SEC
MODULE MDerived IMPORTS MBase
[UPDATE] SEC MetaData
DESC := TL.Desc_Derived ;
END_SEC
[UPDATE] SEC Parameters
[UPDATE,HIDE] SEC Param : paramIn
Variable := xIn ;
DEFAULT := TRUE ;
END_SEC
END_SECIn diesem Beispiel wird der Parameter paramIn des Modules MBase im abgeleiteten Modul MDerived mit HIDE verborgen und gleichzeitig mit einem neuen Defaultwert (TRUE) versehen.
Anmerkung zur Reihenfolge von Abschnitten und Definitionen
Die Reihenfolge der Abschnitte direkt nach dem Modul-Header spielt keine Rolle. Innerhalb der Abschnitte kann die Reihenfolge allerdings sehr wohl eine Rolle spielen. Zum Beispiel bestimmt die Reihenfolge der Slot-Deklarationen die Reihenfolge, in der die Slots im Modulbaum angezeigt werden.
Die Reihenfolge von Definitionen spielt nie eine Rolle.
Die Abschnitte eines Basismoduls kommen immer vor den im Modul selbst definierten Abschnitten.
Wird ein Abschnitt aus dem Basismodul mit
UPDATEoderHIDEverändert, so hat das keine Auswirkung auf seine Reihenfolge.Für ein abgeleitetes Modul ist es nicht möglich ist, die Reihenfolge, wie sie im Basismodul vorgegeben ist, zu verändern.
Autovervollständigung und „Komponenten auflisten“
Beim Schreiben im Moduleditor werden alle möglichen verfügbaren Sekionsdefinitionen in einem „Komponenten auflisten“-Menü angezeigt. Dabei werden nur sinnvolle Sektionen und Definitionen für die aktuelle Position gezeigt. Selbst wenn einige Untersektionseinträge den gleichen Namen wie Untersektionseinträge anderer Sektionen haben, wird versucht, nur die passenden Sektionsdefinitionen anzuzeigen.
Wenn nach der Fertigstellung der ersten Zeile einer Sektion Return gedrückt wird, wird die Sektion mit allen notwendigen Definitionen/Sektionen und dem END_SEC vervollständigt.
Nach den Variablendefinitionen werden Eingangs- und Ausgangsvariablen durch eine „Komponenten auflisten“-Menü angeboten. Flags oder vordefinierte Werte werden ebenfalls in einer „Komponenten auflisten“-Auswahl, die die möglichen Flags/Werte anzeigt, angeboten.
Nach Definitionen, welche Textlisteneinträge oder Einträge von Bildersammlungen verwenden (in den meisten Fällen Desc :=), wird ein „Komponenten auflisten“-Menü mit allen verfügbaren und sichtbaren Textlisten/Bildersammlungen und deren Einträgen angezeigt.
Durch Drücken von F2 kann die entsprechende Eingabeunterstützung geöffnet werden.