CODESYS String Libraries
导言
中的图书馆 CODESYS String Libraries 包可用于处理采用 UTF-8 编码的字符串。基础是 IString 接口来自 String Segments 图书馆。使用此接口,可以通过引用将字符串传递给相应的函数。例如,要创建一个 IString 实例, GSB.UTF8String 中的功能块 Generic String Base 提供了库。
| 的基础函数 | |
| 高效管理 UTF-8 编码的字符串段 | |
| 将不同编码的字符串转换为 UTF-8 | |
| 按照传统标准库的示例处理 UTF-8 编码字符串的函数。 | |
| 用于处理 Unicode 字符类别的函数。 | |
| 处理 UTF-16 编码内存区域的基本函数 | |
| 处理 UTF-8 编码内存区域的基本函数 | |
| 用于处理 UTF-8 编码字符串的功能块,这些字符串通过静态管理其内存 |
新字符串库的优点
重要
新的字符串库并不能取代以前熟悉的字符串函数 Standard 和 Standard64 图书馆。不过,我们建议在新项目中使用新的字符串库。
新的字符串库还可以高效地处理大型字符串。字符串的长度几乎是无限的。因此,这些库也适用于编辑大型文本文件和网页内容。
UTF-8 是一种可以根据 UNICODE 表示全部字符范围的编码。
UTF-8 在互联网上被广泛使用,由万维网联盟 (W3C) 推荐。
由于 ASCII 兼容,UTF-8 与传统系统兼容。
UTF-8 提供了高水平的互操作性。
UTF-8 用于优化内存。
新的字符串库允许您通过相应的方法查询先前定义的字符串,就像您在其他高级语言中知道的那样。
Len()udiStringLen := myString.Len(); if udiStringLen = 22 THEN ...
截至 CODESYS 3.5.18.0,你可以设置编译器来解释类型变量的内容 STRING 作为 UTF-8 编码。你选择 字符串的 UTF8 编码 中的选项 项目设置 在 编译选项 类别。
如果你不想治疗所有人 STRING 项目中的变量采用 UTF-8 编码,则需要清除此选项。之后,您可以将 UTF-8 编码应用于单个文字 STRING 根据具体情况键入。
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';由于 UTF-8 编码的功能,您不必使用 WSTRING 中的数据类型 CODESYS 使用扩展字符集。UCS-2 编码,其中 WSTRING 是基于,可能需要比 UTF-8 编码更多的内存,具体取决于应用程序。UCS-2 编码始终使用一个 WORD 每个字符,只能代表字符 U+0000 到 U+D800 和 U+DFFF 到 U+FFFD。UTF-8 编码要求每个字符一到四个字节。因此,可以处理所有 Unicode 字符。
使用 UTF-8 编码,如果你尝试使用特定索引获取特定字符,那么由于长度可变,这将导致意想不到的结果。
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
byValue := sValue[13]; // The 'u' is NOT the 13th character in the string
xOk := byValue <> 16#75;你需要通过迭代字符串来确定字符的索引。
VAR
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
fbsValue : STR.UTF8Literal := (psValue:=ADR(sValue));
fbRange : STR.Range := (itfString:=fbsValue);
diRune : STR.RUNE;
udiIndex, udiLength : UDINT;
xOk : BOOL;
END_VAR
WHILE (diRune := fbRange.GetNextRune(udiLength=>udiLength)) <> 0 DO
IF diRune = 16#75 (* 'u' *) THEN
EXIT;
END_IF
udiIndex := udiIndex + udiLength;
END_WHILE
xOk := sValue[udiIndex] = 16#75 (* 'u' *);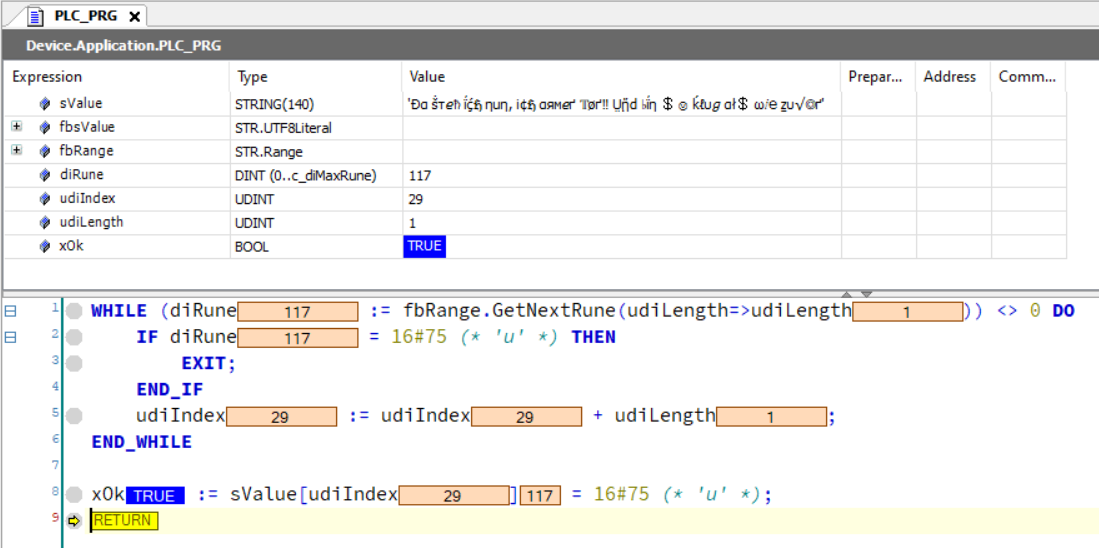
既定机构的缺点 STRING 函数
在先前建立的 STRING 标准库中的函数,类型的参数 STRING 当它们传递给函数时会被复制。返回值也被复制到带有赋值的变量中。
VAR
sValue : STRING;
END_VAR
sValue := CONCAT(CONCAT(CONCAT('Da steh ich nun,', ' ich armer Tor!'), ' Und bin so'), ' klug als wie zu vor');
// -> Copy, LEN -> Copy, LEN -> Copy, LEN -> Copy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LEN在处理类型的参数之前 STRING 在相应的函数中,它们的长度通常必须通过迭代来确定,直到终止的空字符。对于较长的字符串,这些复制和迭代操作会增加应用程序的处理时间。为了应用这些函数,字符串的长度限制为 255 个字符。
使用 IString 接口
这个 STR.IString 引入接口是为了传递数据结构,该数据结构通过引用管理有关字符串的信息。这是与之前建立的 STRING 函数的主要区别,后者没有实现 STR.IString 接口。
此外,字符串的大小(UTF-8 编码字符的相应内存)可能在数字范围内 UDINT 4 ≦ udiSize ≦ 16#FFFF_FF00)。
引用相应的存储器段
当前容量 (→
GetSegment)长度 (→
Len) 以字节为单位字符数 (→
RuneCount)
STR.IStringVAR
itfString : STR.IString;
udiLength, udiSize, udiRuneCount : UDINT;
pbySegment : POINTER TO BYTE;
xValid : BOOL;
END_VAR
udiLength := itfString.Len(); // Current length in byte
pbySegment := itfString.GetSegment(udiSize=>udiSize); // Address first byte, capacity of the segment in bytes
udiRuneCount := STR.RuneCount(itfString); // Current number of "characters" in the segment
xValid := itfString.IsValid(); // Indication that a valid UTF-8 encoding is present.相关性:“角色” 和 “符文”
术语 “rune” 出现在库和源代码中,其含义与 “Unicode 代码点” 完全相同,但有一个有趣的补充。
这些库将 “rune” 一词定义为该类型的别名 DINT。因此,用户可以清楚地看到整数值何时代表代码点。此外,可以想象为字符常量的东西称为符文常
示例:表达式的类型和值 WSTRING#"⌘" 是带有整数值的符文 DINT#16#2318。