CODESYS String Libraries
はじめに
の図書館 CODESYS String Libraries パッケージは UTF-8 でエンコードされた文字列の処理に使用できます。基本は IString からのインターフェイス String Segments ライブラリ。このインターフェースを使うと、文字列をそれぞれの関数に参照渡すことができます。たとえば、を作成するには IString インスタンス、 GSB.UTF8String からのファンクションブロック Generic String Base ライブラリが提供されています。
| の基本機能 | |
| UTF-8 でエンコードされた文字列セグメントの効率的な管理 | |
| 異なるエンコーディングの文字列のUTF-8への変換、またはUTF-8からの変換 | |
| 従来の標準ライブラリの例に従ってUTF-8でエンコードされた文字列を処理する関数。 | |
| Unicode 文字カテゴリを処理するための関数。 | |
| UTF-16 でエンコードされたメモリ領域を処理するための基本関数 | |
| UTF-8 でエンコードされたメモリ領域を処理するための基本関数 | |
| メモリを静的に管理するUTF-8でエンコードされた文字列を処理するためのファンクションブロック |
新しい文字列ライブラリの利点
重要
新しい文字列ライブラリは、使い慣れた古い文字列関数に取って代わるものではありません。 Standard と Standard64 ライブラリ。とはいえ、新しいプロジェクトには新しい文字列ライブラリを使用することをお勧めします。
新しい文字列ライブラリでは、大きな文字列も効率的に処理できます。文字列の長さはほぼ無制限です。そのため、ライブラリはサイズの大きいテキストファイルや Web コンテンツの編集にも適しています。
UTF-8は、すべての文字をUNICODEに従って表現できるエンコーディングです。
UTF-8 はインターネット上で広く使用されており、ワールド・ワイド・ウェブ・コンソーシアム (W3C) によって推奨されています。
UTF-8 は ASCII 互換のため、レガシーシステムと互換性があります。
UTF-8 は高レベルの相互運用性を提供します。
UTF-8 はメモリの最適化に役立ちます。
新しい文字列ライブラリでは、他の高級言語と同じように、対応するメソッドを使用して以前に定義した文字列をクエリできます。
Len()udiStringLen := myString.Len(); if udiStringLen = 22 THEN ...
現在 CODESYS 3.5.18.0 では、型変数の内容を解釈するようにコンパイラーを設定できます。 STRING UTF-8 エンコーディングとして。を選択します。 文字列の UTF-8 エンコーディング の「オプション」 [プロジェクト設定] で コンパイルオプション カテゴリー。
すべてを治療したくない場合 STRING プロジェクト内の変数が UTF-8 でエンコードされている場合は、このオプションをオフにする必要があります。その後、の個々のリテラルに UTF-8 エンコーディングを適用できます STRING ケースバイケースで入力してください。
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';UTF-8 エンコーディングの機能のおかげで、UTF-8 エンコーディングを使用する必要はありません WSTRING データタイプ: CODESYS 拡張文字セットを使用すること。UCS-2 エンコーディング WSTRING をベースにしているため、アプリケーションによっては UTF-8 エンコーディングよりも多くのメモリが必要になる場合があります。UCS-2 エンコーディングでは常に WORD 1 文字あたり。1 文字のみを表すことができます。 U+0000 に U+D800 そして U+DFFF へ U+FFFD。UTF-8 エンコーディングには、1 文字あたり 1 バイトから 4 バイトが必要です。その結果、すべての Unicode 文字を処理できます
UTF-8 エンコーディングでは、特定のインデックスを使用して特定の文字を取得しようとすると、可変長が原因で予期しない結果になります。
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
byValue := sValue[13]; // The 'u' is NOT the 13th character in the string
xOk := byValue <> 16#75;文字列を繰り返し処理して文字のインデックスを決定する必要があります。
VAR
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
fbsValue : STR.UTF8Literal := (psValue:=ADR(sValue));
fbRange : STR.Range := (itfString:=fbsValue);
diRune : STR.RUNE;
udiIndex, udiLength : UDINT;
xOk : BOOL;
END_VAR
WHILE (diRune := fbRange.GetNextRune(udiLength=>udiLength)) <> 0 DO
IF diRune = 16#75 (* 'u' *) THEN
EXIT;
END_IF
udiIndex := udiIndex + udiLength;
END_WHILE
xOk := sValue[udiIndex] = 16#75 (* 'u' *);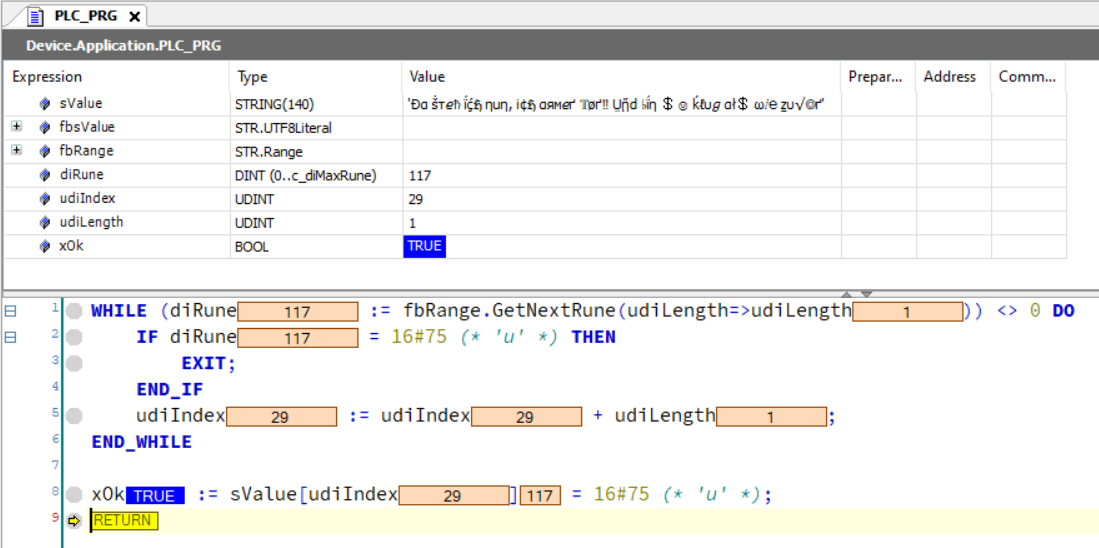
確立された企業のデメリット STRING 関数
以前に設立された STRING 標準ライブラリの関数 (型のパラメーター) STRING 関数に渡されるときにコピーされます。戻り値も代入された変数にコピーされます。
VAR
sValue : STRING;
END_VAR
sValue := CONCAT(CONCAT(CONCAT('Da steh ich nun,', ' ich armer Tor!'), ' Und bin so'), ' klug als wie zu vor');
// -> Copy, LEN -> Copy, LEN -> Copy, LEN -> Copy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LENタイプのパラメータを処理する前に STRING それぞれの関数では、その長さは終端の NULL 文字まで繰り返し処理して決定しなければならないことが多い。文字列が長い場合、このようなコピー操作や繰り返し操作を行うと、アプリケーションの処理時間が長くなります。これらの関数を適用する場合、文字列の長さは 255 文字に制限されています
を使用する IString インターフェイス
ザル STR.IString 文字列に関する情報を管理するデータ構造を参照渡しするためのインタフェースが導入されました。これは、これを実装していない以前に確立された STRING 関数との大きな違いです STR.IString インターフェイス。
さらに、文字列のサイズ (UTF-8 でエンコードされた文字に対応するメモリ) は、数値範囲内であってもかまいません。 UDINT 4 ≦ udiSize ≦ 16#FFFF_FF00)。
それぞれのメモリセグメントへの参照
現在の容量 (→
GetSegment)長さ (→
Len) (バイト単位)文字数 (→
RuneCount)
STR.IStringVAR
itfString : STR.IString;
udiLength, udiSize, udiRuneCount : UDINT;
pbySegment : POINTER TO BYTE;
xValid : BOOL;
END_VAR
udiLength := itfString.Len(); // Current length in byte
pbySegment := itfString.GetSegment(udiSize=>udiSize); // Address first byte, capacity of the segment in bytes
udiRuneCount := STR.RuneCount(itfString); // Current number of "characters" in the segment
xValid := itfString.IsValid(); // Indication that a valid UTF-8 encoding is present.相関関係:「キャラクター」と「ルーン」
「ルーン」という用語は、ライブラリやソースコードに使われていますが、「Unicodeコードポイント」とまったく同じ意味ですが、興味深い追加点があります。
ライブラリでは、「ルーン」という単語をタイプのエイリアスとして定義しています DINT。その結果、整数がいつコードポイントを表しているかがユーザーにはっきりとわかります。さらに、文字定数として想像できるものをルーン定数といいます
例:式のタイプと値 WSTRING#"⌘" は整数値を持つルーン文字です DINT#16#2318。