CODESYS String Libraries
Introduzione
Le biblioteche del CODESYS String Libraries pacchetto può essere utilizzato per elaborare stringhe codificate in UTF-8. La base è IString interfaccia da String Segments libreria. Utilizzando questa interfaccia, le stringhe possono essere passate alle rispettive funzioni per riferimento. Ad esempio, per creare un IString istanza, il GSB.UTF8String blocco funzione del Generic String Base viene fornita la libreria.
| Funzioni base per | |
| Gestione efficiente dei segmenti di stringa con codifica UTF-8 | |
| Conversione di stringhe con codifica diversa da/verso UTF-8 | |
| Funzioni per l'elaborazione di stringhe codificate UTF-8 seguendo l'esempio della libreria standard convenzionale. | |
| Funzioni per l'elaborazione di categorie di caratteri Unicode. | Documentazione della libreria delle funzioni di supporto Unicode |
| Funzione base per la gestione delle aree di memoria codificate UTF-16 | Documentazione della libreria di supporto alla codifica UTF-16 |
| Funzione base per la gestione delle aree di memoria codificate UTF-8 | Documentazione della libreria delle funzioni di supporto alla codifica UTF-8 |
| Blocchi funzionali per l'elaborazione di stringhe codificate UTF-8 che gestiscono la loro memoria staticamente tramite | Documentazione generica della libreria String Base Functions |
Vantaggi delle nuove librerie di stringhe
Importante
Le nuove librerie di stringhe non sostituiscono le vecchie e familiari funzioni di stringa di Standard e Standard64 librerie. Tuttavia, consigliamo di utilizzare le nuove librerie di stringhe per nuovi progetti.
Le nuove librerie di stringhe possono anche gestire stringhe di grandi dimensioni in modo efficiente. La lunghezza delle stringhe è quasi illimitata. Per questo motivo, le librerie sono adatte anche per modificare file di testo e contenuti web di grandi dimensioni
UTF-8 è una codifica che può rappresentare l'intera gamma di caratteri secondo UNICODE.
UTF-8 è ampiamente utilizzato su Internet ed è raccomandato dal World Wide Web Consortium (W3C).
UTF-8 è compatibile con i sistemi precedenti grazie alla compatibilità ASCII.
UTF-8 offre un elevato livello di interoperabilità.
UTF-8 funziona per ottimizzare la memoria.
Le nuove librerie di stringhe consentono di interrogare una stringa definita in precedenza tramite i metodi corrispondenti, proprio come la si conosce in altri linguaggi di alto livello.
Len()udiStringLen := myString.Len(); if udiStringLen = 22 THEN ...
A partire da CODESYS 3.5.18.0, è possibile impostare il compilatore per interpretare il contenuto delle variabili di tipo STRING come codifica UTF-8. Si seleziona il Codifica UTF8 per STRING opzione in Impostazioni del progetto nel Opzioni di compilazione categoria.
Se non vuoi trattare tutto STRING variabili in un progetto con codifica UTF-8, quindi è necessario deselezionare questa opzione. Dopodiché, puoi applicare la codifica UTF-8 STRING digitare caso per caso.
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';Grazie alle funzionalità della codifica UTF-8, non è necessario utilizzare WSTRING tipo di dati in CODESYS per utilizzare un set di caratteri esteso. codifica UCS-2 WSTRING è basato su, può richiedere più memoria rispetto a una codifica UTF-8, a seconda dell'applicazione. La codifica UCS-2 WORD per carattere e può rappresentare solo i personaggi U+0000 a U+D800 e U+DFFF a U+FFFD. La codifica UTF-8 richiede da uno a quattro byte per carattere. Di conseguenza, tutti i caratteri Unicode
Con la codifica UTF-8, se si tenta di ottenere un carattere specifico utilizzando un indice specifico, ciò porterà a risultati imprevisti a causa della lunghezza variabile.
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
byValue := sValue[13]; // The 'u' is NOT the 13th character in the string
xOk := byValue <> 16#75;È necessario determinare l'indice di un carattere iterando la stringa.
VAR
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
fbsValue : STR.UTF8Literal := (psValue:=ADR(sValue));
fbRange : STR.Range := (itfString:=fbsValue);
diRune : STR.RUNE;
udiIndex, udiLength : UDINT;
xOk : BOOL;
END_VAR
WHILE (diRune := fbRange.GetNextRune(udiLength=>udiLength)) <> 0 DO
IF diRune = 16#75 (* 'u' *) THEN
EXIT;
END_IF
udiIndex := udiIndex + udiLength;
END_WHILE
xOk := sValue[udiIndex] = 16#75 (* 'u' *);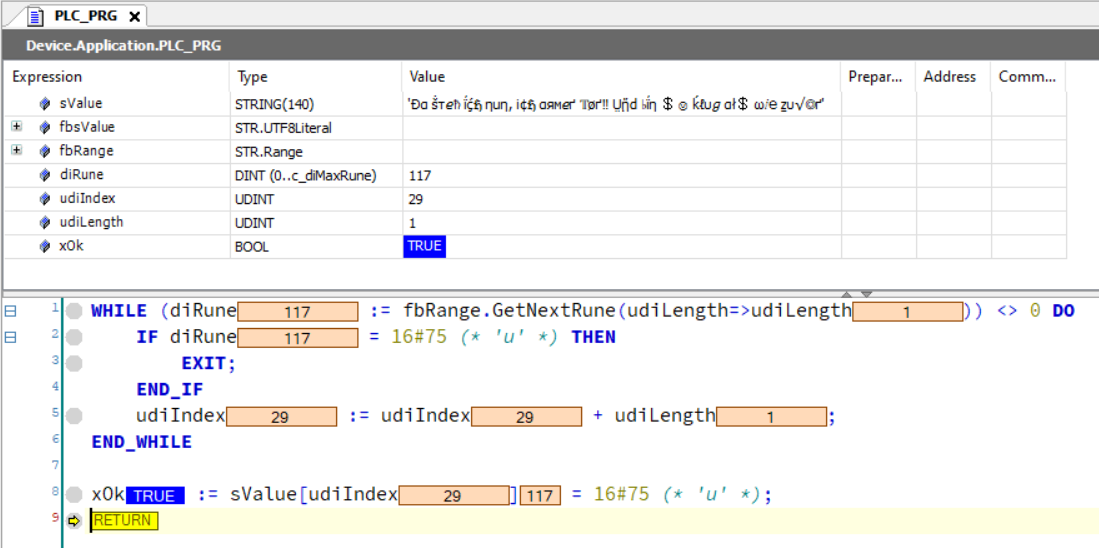
Svantaggi del consolidato STRING funzioni
Nel precedentemente stabilito STRING funzioni della libreria standard, i parametri di tipo STRING vengono copiati quando vengono passati alle funzioni. Il valore restituito viene inoltre copiato in una variabile con l'
VAR
sValue : STRING;
END_VAR
sValue := CONCAT(CONCAT(CONCAT('Da steh ich nun,', ' ich armer Tor!'), ' Und bin so'), ' klug als wie zu vor');
// -> Copy, LEN -> Copy, LEN -> Copy, LEN -> Copy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LENPrima di elaborare i parametri di tipo STRING nelle rispettive funzioni, le loro lunghezze devono spesso essere determinate mediante iterazione fino al carattere nullo di terminazione. Per stringhe più lunghe, queste operazioni di copia e iterazione aumentano il tempo di elaborazione dell'applicazione. La lunghezza delle stringhe è limitata a 255 caratteri per l'applicazione di
Usando il IString interfaccia
Le STR.IString l'interfaccia è stata introdotta per passare la struttura dati che gestisce le informazioni su una stringa per riferimento. Questa è una grande differenza rispetto alle funzioni STRING precedentemente stabilite, che non implementano STR.IString interfaccia.
Inoltre, la dimensione di una stringa (la rispettiva memoria per i caratteri codificati UTF-8) può essere compresa nell'intervallo numerico UDINT 4 ≦ udiSize ≦ 16#FFFF_FF00).
Riferimento al rispettivo segmento di memoria
Capacità attuale (→
GetSegment)Lunghezza (→
Len) in byteNumero di caratteri (→
RuneCount)
STR.IStringVAR
itfString : STR.IString;
udiLength, udiSize, udiRuneCount : UDINT;
pbySegment : POINTER TO BYTE;
xValid : BOOL;
END_VAR
udiLength := itfString.Len(); // Current length in byte
pbySegment := itfString.GetSegment(udiSize=>udiSize); // Address first byte, capacity of the segment in bytes
udiRuneCount := STR.RuneCount(itfString); // Current number of "characters" in the segment
xValid := itfString.IsValid(); // Indication that a valid UTF-8 encoding is present.Correlazione: «personaggio» e «runa»
Il termine «runa» appare nelle librerie e nel codice sorgente e significa esattamente lo stesso di «punto di codice Unicode», con un'interessante aggiunta.
Le librerie definiscono la parola «rune» come alias per il tipo DINT. Di conseguenza, l'utente può vedere chiaramente quando un valore intero rappresenta un punto di codice. Inoltre, ciò che può essere immaginato come una costante di carattere è chiamata costante runica
Esempio: il tipo e il valore dell'espressione WSTRING#"⌘" è una runa con valore intero DINT#16#2318.