Preelaborazione del percorso e dimensioni della coda
Pipeline dell'elaborazione del codice G
Quando il codice G viene letto da un file, spesso non è pratico leggere ed elaborare l'intero file prima di iniziare la lavorazione. Per alcune applicazioni, i file G-code possono avere alcune centinaia di migliaia o addirittura milioni di righe. Leggere tutto in una volta richiederebbe molto tempo e anche molta memoria
Invece, il codice G viene letto riga per riga, ma solo una piccola parte (poche centinaia di righe) viene conservata in memoria in ogni momento. Questa parte viene mantenuta in code, cioè in strutture dati che funzionano secondo il principio «first in, first out»: il blocco funzionale che produce aggiunge elementi alla coda. Il blocco funzionale che consuma legge e rimuove gli elementi nello stesso ordine in cui sono stati inseriti
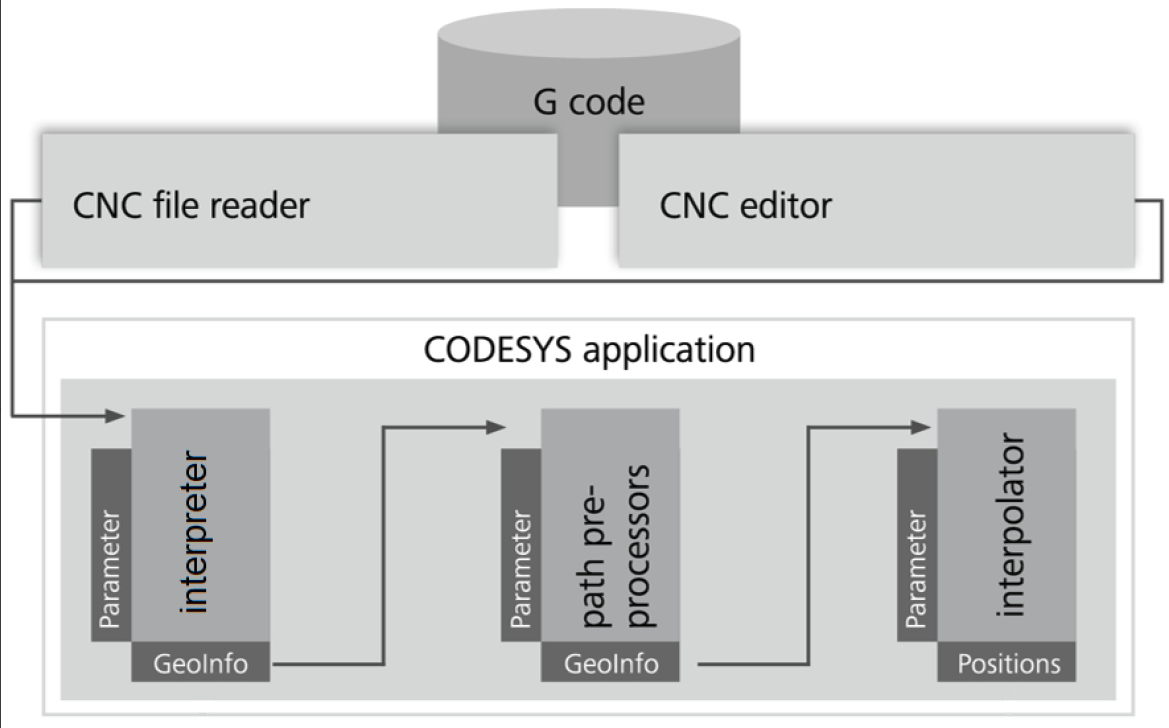
Il diagramma mostra il flusso del codice G attraverso il sistema. Innanzitutto, il codice G viene letto da un file, quindi convertito in cosiddetti elementi GeoInfo dall'interprete. Questi elementi vengono elaborati dai blocchi funzionali di preelaborazione del percorso e infine interpolati. Le parti contrassegnate da «GeoInfo» rappresentano le code. Se più di un preprocessore di percorso SMC_SmoothPath, SMC_ToolRadiusCorr, oppure SMC_AvoidLoop) viene utilizzato, quindi sono anche collegati da code.
Dimensioni della coda consigliate
Come regola generale, per la maggior parte delle code è adatta una dimensione di 16 elementi. L'ultima coda prima SMC_Interpolator blocco di funzioni (che di solito è la coda del percorso, il blocco funzionale precedente alla preelaborazione) SMC_CheckVelocities) dovrebbe avere una dimensione della coda maggiore: 100 elementi sono un buon punto di partenza per la maggior parte delle applicazioni.
Latenza di elaborazione: più grandi sono le code, più tempo ci vorrà per riempirle inizialmente. Le
SMC_Interpolatorblocco funzione attende il riempimento dell'ultima coda prima di iniziare con l'interpolazione. Per la latenza, è rilevante la dimensione totale della coda (somma di tutte le dimensioni della codaGuardare avanti dell'interpolatore: la dimensione dell'ultima coda prima del
SMC_Interpolatordetermina il lookahead dell'interpolazione. Quando calcola una traiettoria, l'interpolatore può pianificare solo fino alla fine del lookahead. Se il lookahead è troppo piccolo, l'interpolatore potrebbe non essere in grado di raggiungere l'intera velocità del percorso. A seconda della velocità del percorso e della lunghezza degli elementi, 100 elementi sono un buon punto di partenza, ma per elementi ad alta velocità e/o brevi, potrebbe essere necessaria una dimensione della codaEffetto su blocchi funzionali particolari: Blocchi funzionali come
SMC_AvoidLoopoSMC_SmoothMergerichiedono una certa dimensione della coda in entrata per funzionare in modo efficace. Ad esempio, per rilevare un loop nel G-Code, questo loop deve essere inseritoSMC_AvoidLoop. Per i dettagli, consultate la documentazione dei blocchi funzionali nella pipeline di elaborazione dei percorsi
Chiamata dei blocchi funzionali di elaborazione
Come accennato in precedenza, l'interpolazione inizia solo dopo che tutte le code sono state riempite. Ciò causa una latenza iniziale all'avvio della lavorazione. Oltre a ridurre la dimensione totale della coda, esiste un altro modo per ridurre
I blocchi funzionali di preelaborazione del percorso vengono generalmente richiamati in un'attività ciclica in background, come mostrato negli esempi come Esempio CNC 03: esecuzione della preelaborazione del percorso in linea. Per ridurre la latenza, il programma chiama SMC_ReadNCFile2, SMC_NCInterpretere i preprocessori di percorso possono essere richiamati in un ciclo. A seconda delle priorità dell'applicazione e dell'attività, può essere sufficiente eseguire il programma più volte per chiamata all'operazione (ad esempio 100 volte) o terminare il ciclo dopo un determinato intervallo di tempo (ad esempio 5