CODESYS String Libraries
Présentation
Les bibliothèques du CODESYS String Libraries Le package peut être utilisé pour traiter des chaînes codées en UTF-8. La base est IString interface depuis String Segments bibliothèque. À l'aide de cette interface, les chaînes peuvent être transmises aux fonctions respectives par référence. Par exemple, pour créer un IString exemple, le GSB.UTF8String bloc de fonction du Generic String Base une bibliothèque est fournie.
| Fonctions de base pour | |
| Gestion efficace des segments de chaînes codés en UTF-8 | |
| Conversion de chaînes de différents encodages vers/depuis UTF-8 | |
| Fonctions de traitement de chaînes codées en UTF-8 en suivant l'exemple de la bibliothèque standard conventionnelle. | |
| Fonctions de traitement des catégories de caractères Unicode. | Documentation de la bibliothèque des fonctions de support Unicode |
| Fonction de base pour gérer les zones de mémoire codées en UTF-16 | Documentation de la bibliothèque de support de l'encodage UTF-16 |
| Fonction de base pour gérer les zones de mémoire codées en UTF-8 | Documentation de la bibliothèque des fonctions de support de l'encodage UTF-8 |
| Blocs fonctionnels pour le traitement de chaînes codées en UTF-8 qui gèrent leur mémoire de manière statique via | Documentation de la bibliothèque de fonctions de base de chaînes génériques |
Avantages des nouvelles bibliothèques de chaînes
Important
Les nouvelles bibliothèques de chaînes ne remplacent pas les anciennes fonctions de chaîne familières du Standard et Standard64 bibliothèques. Néanmoins, nous vous recommandons d'utiliser les nouvelles bibliothèques de chaînes pour les nouveaux projets.
Les nouvelles bibliothèques de chaînes peuvent également gérer de grandes chaînes de manière efficace. La longueur des cordes est quasiment illimitée. Pour cette raison, les bibliothèques sont également adaptées à l'édition de fichiers texte volumineux et de contenus Web.
L'UTF-8 est un codage qui peut représenter la gamme complète de caractères selon UNICODE.
L'UTF-8 est largement utilisé sur Internet et est recommandé par le World Wide Web Consortium (W3C).
L'UTF-8 est compatible avec les systèmes existants en raison de la compatibilité ASCII.
L'UTF-8 offre un haut niveau d'interopérabilité.
L'UTF-8 fonctionne pour optimiser la mémoire.
Les nouvelles bibliothèques de chaînes vous permettent d'interroger une chaîne précédemment définie via les méthodes correspondantes, comme vous le savez dans d'autres langages de haut niveau.
Len()udiStringLen := myString.Len(); if udiStringLen = 22 THEN ...
À partir du CODESYS 3.5.18.0, vous pouvez configurer le compilateur pour interpréter le contenu des variables de type STRING sous forme de codage UTF-8. Vous sélectionnez le Encodage UTF8 pour STRING option dans le Paramètres du projet dans le Options de compilation catégorie.
Si vous ne souhaitez pas tout traiter STRING variables d'un projet codées en UTF-8, vous devez désactiver cette option. Ensuite, vous pouvez appliquer le codage UTF-8 à des littéraux individuels STRING tapez au cas par cas.
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';Grâce aux capacités de l'encodage UTF-8, vous n'avez pas besoin d'utiliser WSTRING type de données dans CODESYS pour utiliser un jeu de caractères étendu. encodage UCS-2 WSTRING est basé sur, peut nécessiter plus de mémoire qu'un codage UTF-8, selon l'application. Le codage UCS-2 en utilise toujours WORD par caractère et ne peut représenter que les personnages U+0000 à U+D800 et U+DFFF à U+FFFD. Le codage UTF-8 nécessite entre un et quatre octets par caractère. Par conséquent, tous les caractères Unicode peuvent être traités
Avec le codage UTF-8, si vous essayez d'obtenir un caractère spécifique à l'aide d'un index spécifique, cela entraînera des résultats inattendus en raison de la longueur variable.
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
byValue := sValue[13]; // The 'u' is NOT the 13th character in the string
xOk := byValue <> 16#75;Vous devez déterminer l'index d'un caractère en parcourant la chaîne.
VAR
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
fbsValue : STR.UTF8Literal := (psValue:=ADR(sValue));
fbRange : STR.Range := (itfString:=fbsValue);
diRune : STR.RUNE;
udiIndex, udiLength : UDINT;
xOk : BOOL;
END_VAR
WHILE (diRune := fbRange.GetNextRune(udiLength=>udiLength)) <> 0 DO
IF diRune = 16#75 (* 'u' *) THEN
EXIT;
END_IF
udiIndex := udiIndex + udiLength;
END_WHILE
xOk := sValue[udiIndex] = 16#75 (* 'u' *);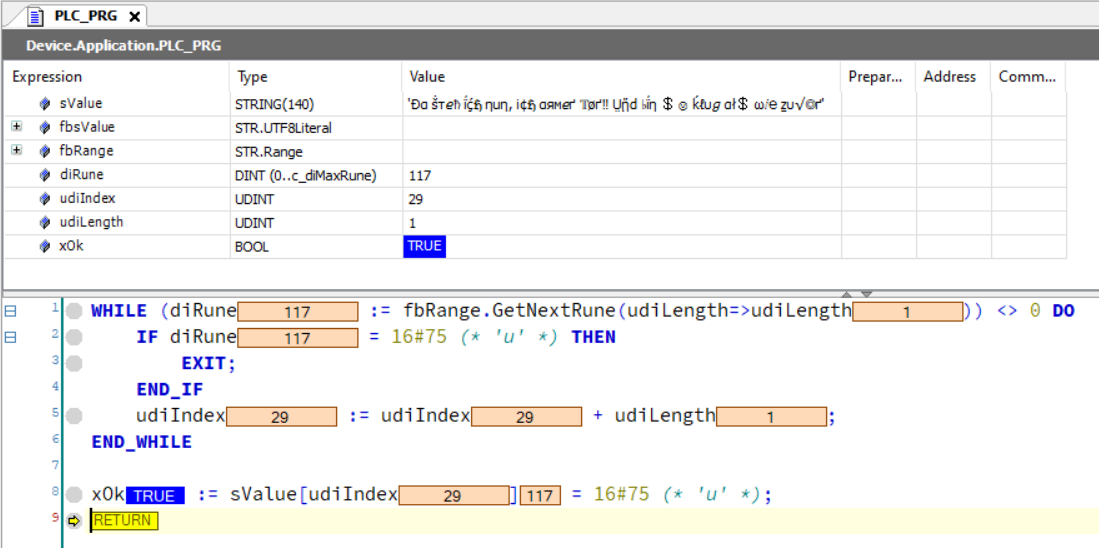
Inconvénients de l'établi STRING fonctions
Dans le cadre précédemment établi STRING fonctions de la bibliothèque standard, les paramètres de type STRING sont copiés lorsqu'ils sont transmis aux fonctions. La valeur de retour est également copiée dans une variable avec l'affectation.
VAR
sValue : STRING;
END_VAR
sValue := CONCAT(CONCAT(CONCAT('Da steh ich nun,', ' ich armer Tor!'), ' Und bin so'), ' klug als wie zu vor');
// -> Copy, LEN -> Copy, LEN -> Copy, LEN -> Copy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LENAvant de traiter les paramètres de type STRING dans les fonctions respectives, leur longueur doit souvent être déterminée par itération jusqu'au caractère nul final. Pour les chaînes plus longues, ces opérations de copie et d'itération augmentent le temps de traitement de l'application. La longueur des chaînes est limitée à 255 caractères pour l'application de ces fonctions.
À l'aide du IString interface
Le STR.IString interface a été introduite pour transmettre la structure de données qui gère les informations relatives à une chaîne par référence. Il s'agit d'une différence majeure par rapport aux fonctions STRING précédemment établies, qui n'implémentent pas le STR.IString interface.
De plus, la taille d'une chaîne (la mémoire respective pour les caractères codés UTF-8) peut être comprise dans la plage numérique UDINT 4 ≦ udiSize ≦ 16#FFFF_FF00).
Référence au segment de mémoire correspondant
Capacité actuelle (→
GetSegment)Longueur (→
Len) en octetsNombre de caractères (→
RuneCount)
STR.IStringVAR
itfString : STR.IString;
udiLength, udiSize, udiRuneCount : UDINT;
pbySegment : POINTER TO BYTE;
xValid : BOOL;
END_VAR
udiLength := itfString.Len(); // Current length in byte
pbySegment := itfString.GetSegment(udiSize=>udiSize); // Address first byte, capacity of the segment in bytes
udiRuneCount := STR.RuneCount(itfString); // Current number of "characters" in the segment
xValid := itfString.IsValid(); // Indication that a valid UTF-8 encoding is present.Corrélation : « personnage » et « rune »
Le terme « rune » apparaît dans les bibliothèques et dans le code source et signifie exactement la même chose que « point de code Unicode », avec un ajout intéressant.
Les bibliothèques définissent le mot « rune » comme alias pour le type DINT. Par conséquent, l'utilisateur peut clairement voir quand une valeur entière représente un point de code. De plus, ce que l'on peut imaginer comme une constante de caractère est appelé constante runique
Exemple : type et valeur de l'expression WSTRING#"⌘" est une rune dont la valeur est un entier DINT#16#2318.