Prétraitement des chemins et tailles des files d'attente
Pipelinage du traitement du code G
Lorsque le code G est lu à partir d'un fichier, il est souvent peu pratique de lire et de traiter l'intégralité du fichier avant de commencer l'usinage. Pour certaines applications, les fichiers G-code peuvent comporter quelques centaines de milliers, voire des millions de lignes. La lecture en une seule fois prendrait beaucoup de temps et nécessiterait également beaucoup de mémoire.
Au lieu de cela, le code G est lu ligne par ligne, mais seule une petite fraction (quelques centaines de lignes) est conservée en mémoire à chaque instant. Cette partie est conservée dans des files d'attente, c'est-à-dire dans des structures de données qui fonctionnent selon le principe « premier entré, premier sorti » : le bloc fonctionnel producteur ajoute des éléments à la file d'attente. Le bloc fonctionnel consommateur lit et supprime les éléments dans l'ordre dans lequel ils ont été insérés.
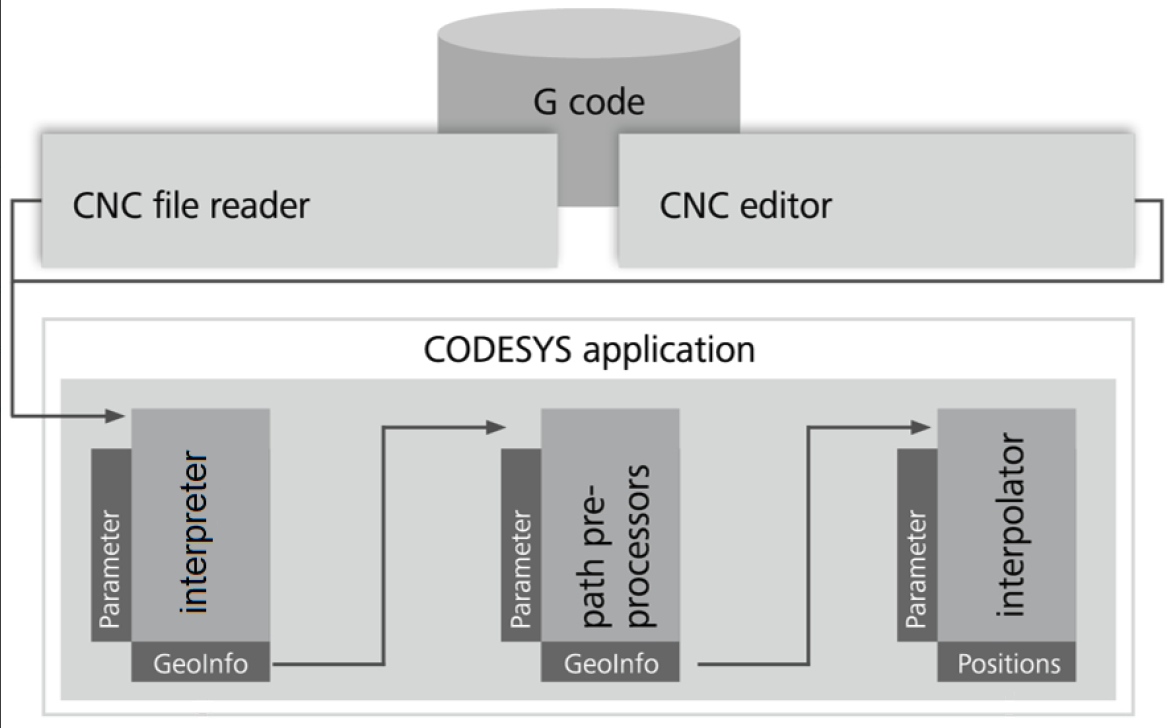
Le schéma montre le flux du code G dans le système. Tout d'abord, le code G est lu à partir d'un fichier, puis converti en éléments dits GeoInfo par l'interpréteur. Ces éléments sont traités par les blocs fonctionnels de prétraitement des chemins et finalement interpolés. Les parties marquées par « GeoInfo » représentent les files d'attente. Si plusieurs préprocesseurs de chemin (tels que SMC_SmoothPath, SMC_ToolRadiusCorr, ou SMC_AvoidLoop) est utilisé, puis ils sont également connectés par des files d'attente.
Tailles de file d'attente recommandées
En règle générale, pour la plupart des files d'attente, une taille de 16 éléments convient. La dernière file d'attente avant SMC_Interpolator bloc fonctionnel (qui est généralement la file d'attente du bloc fonctionnel de prétraitement du chemin avant SMC_CheckVelocities) devrait avoir une taille de file d'attente plus élevée : 100 éléments constituent un bon point de départ pour la plupart des applications.
Latence de traitement : plus les files d'attente sont longues, plus leur remplissage initial sera long.
SMC_Interpolatorbloc de fonctions attend que la dernière file soit remplie avant de commencer l'interpolation. Pour la latence, la taille totale de la file d'attente (somme de toutes les tailles de file d'attente) est pertinente.Regardez vers l'avenir de l'interpolateur : la taille de la dernière file d'attente avant
SMC_Interpolatordétermine la prévision de l'interpolation. Lors du calcul d'une trajectoire, l'interpolateur ne peut planifier que jusqu'à la fin de la prévision. Si la prévision est trop faible, l'interpolateur risque de ne pas être en mesure d'atteindre la vitesse totale du trajet. En fonction de la vitesse de trajet et de la longueur des éléments, 100 éléments constituent un bon point de départ, mais pour les vitesses élevées et/ou les éléments courts, une taille de file d'attente plus importante peut être nécessaireEffet sur blocs fonctionnels particuliers: blocs fonctionnels tels que
SMC_AvoidLoopouSMC_SmoothMergenécessitent une certaine taille de la file d'attente entrante pour fonctionner efficacement. Par exemple, pour détecter une boucle dans le G-Code, cette boucle doit entrer dans la file d'attente avantSMC_AvoidLoop. Consultez la documentation des blocs fonctionnels de votre pipeline de traitement des chemins pour plus de détails.
Appel des blocs de fonctions de traitement
Comme indiqué ci-dessus, l'interpolation ne commence que lorsque toutes les files d'attente sont remplies. Cela entraîne une latence initiale lors du démarrage de l'usinage. Outre la réduction de la taille totale de la file d'attente, il existe un autre moyen de réduire cette latence.
Les blocs de fonctions de prétraitement des chemins sont généralement appelés dans le cadre d'une tâche d'arrière-plan cyclique, comme le montrent les exemples tels que Exemple CNC 03 : Exécution du prétraitement de trajectoire en ligne. Pour réduire la latence, le programme appelant SMC_ReadNCFile2, SMC_NCInterpreter, et les préprocesseurs de chemin peuvent être appelés en boucle. En fonction de l'application et des priorités des tâches, il peut être suffisant d'exécuter le programme plusieurs fois par appel de tâche (par exemple 100 fois) ou de terminer la boucle après un certain laps de temps (par exemple 5 ms).