Déclaration du module
Les modules du CODESYS Application Composer sont définis dans une déclaration de module. La déclaration de module est un objet distinct dans le pool POU et constitue la base de l'utilisation d'un module dans arborescence des modules.
Objets du POU :
Les modules sont déclarés avec leur propre langage de description qui est similaire à la déclaration des variables dans le code ST (texte structuré).
Chaque déclaration de module est basée sur un bloc fonctionnel (module FB).
Le module FB contient la logique fonctionnelle.
La déclaration du module ajoute des informations de configuration et de structure au module FB.
Paramètres
Les variables d'entrée du module FB peuvent être marquées comme paramètres pour permettre un paramétrage structuré du module.
Entrées et sorties du module
Les variables d'entrée et de sortie du module FB peuvent être définies comme des E/S du module et connectées à des variables, à d'autres modules ou à des E/S de périphériques.
Machines à sous
Les slots permettent l'intégration d'autres modules en tant que sous-modules, définissant ainsi une structure de module hiérarchique.
Sous-modules par défaut
Attributions prédéfinies pour les emplacements de module qui sont automatiquement appliquées lors de l'insertion d'un module.
Visualisations
Les modules peuvent fournir des visualisations de pages ainsi que des visualisations intégrées qui sont automatiquement générées et liées.
Module proxy FBs
Les blocs de fonctions proxy peuvent être définis pour implémenter des références au-delà des limites de l'application ou du contrôleur.
Références d'instance
Références aux instances FB que l'utilisateur mappe à des instances spécifiques uniquement au moment de la configuration.
Alarmes
Les modules peuvent utiliser la gestion des alarmes CODESYS pour définir et évaluer des alarmes pour les variables du module FB.
Indicateurs de processus
Indicateurs pour l'utilisation de modules dans des processus séquentiels (par exemple, des chaînes d'étapes).
Format de la déclaration du module
Un en-tête du formulaire MODULE<name> commence la déclaration. Ceci est suivi d'une liste de "sections".
Chaque section est introduite par le mot-clé SEC (pour "section") et un nom unique. Le mot clé END_SEC ferme la section. Le contenu d'une section contient une liste d'entrées composée d'autres sections ou de définitions.
Une définition se compose d'un nom et d'une valeur facultative et se termine par un point-virgule.
Les commentaires peuvent être utilisés comme dans le code ST : "//"" pour un commentaire sur une seule ligne et "(*" et "*)" pour les commentaires multilignes. Les espaces (tabulations et espaces) et les nouvelles lignes/sauts de ligne peuvent être utilisés pour séparer les parties. d'une déclaration, sinon ils seront ignorés lors du traitement ultérieur.
Comme pour le code ST, le respect de la casse ne fait aucune différence.
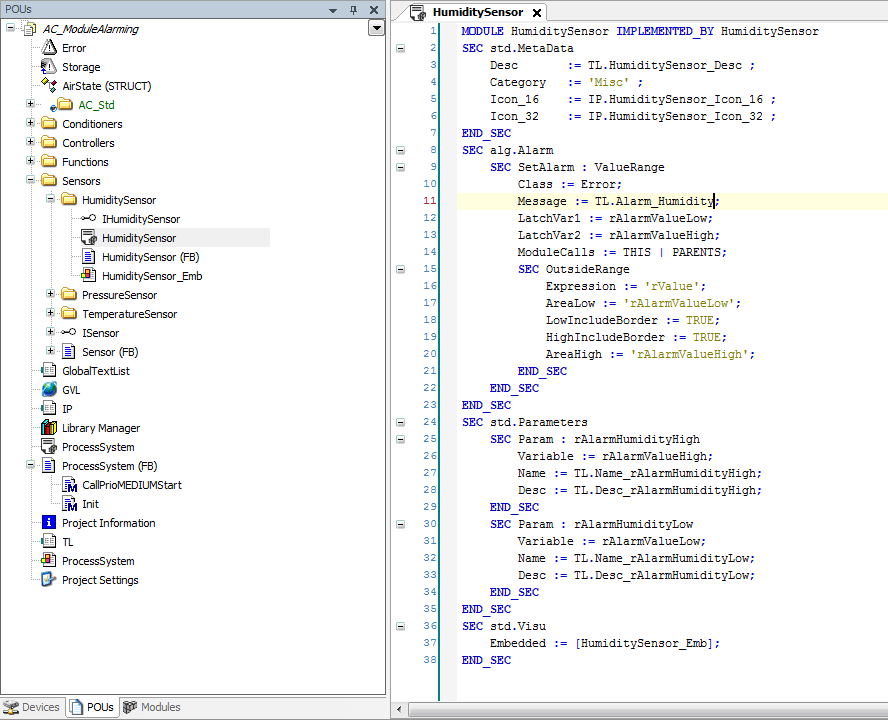
01 MODULE Persistence IMPLEMENTED_BY PersistenceFB 02 SEC MetaData 03 NAME := TL.ChannelName ; 04 DESC := TL.ChannelDesc ; 05 COLLECTION CATEGORY := ’Persistence’TL.Collection ; 06 ICON_16 := IP.Channel16 ; 07 ICON_32 := IP.Channel32 ; 08 END_SEC 09 SEC Toplevel 10 SEC STANDARD_TASK : LOW 11 NAME := LOW ; 12 DESC := TL.TaskLow ; 13 FLAGS := CREATE_IF_MISSING | READONLY ; 14 END_SEC 15 GVL_NAME := 'GVL_%InstanceName%' ; 16 END_SEC
A la ligne 01 se trouve la définition du nom du module "Persistance". IMPLEMENTED_BY définit le bloc fonction "PersitenceFB" qui contient la logique du module. Ce bloc fonction doit dériver de IModule. À la ligne 02, la section MetaData commence et se termine par la ligne 08. Cette section contient cinq définitions. La possibilité de sections imbriquées est indiquée dans la section Toplevel (lignes 09 à 16) qui contient la sous-section STANDARD_TASK (ligne 10).
Syntaxe de la déclaration du module
Dans cette section, la syntaxe et la structure syntaxique autorisée d'une déclaration de module seront expliquées.
Dans le scanner suivant, les jetons seront écrits en majuscules (exemple : ID). Les non-terminaux de la grammaire seront écrits entre accolades (exemple : {Entry}).
Analyse lexicale (scanner)
Dans un premier temps, des jetons (ou lexèmes) seront créés à partir des caractères de la déclaration du module (exemple : mots-clés, constantes, identifiants).
Les espaces ainsi que les caractères de nouvelle ligne et d'entrée de ligne séparent les jetons, mais sont ignorés dans le cas contraire. Les commentaires sont également ignorés lors du traitement de la déclaration. (Les commentaires peuvent être rédigés sur une seule ligne (//«) ou des commentaires multilignes ((* et *)) comme dans le langage ST. Les commentaires multilignes peuvent être imbriqués
Fondamentalement, un jeton a toujours une longueur maximale. Par exemple a123 sera interprété comme un identifiant et non comme un identifiant a suivi d'un littéral 123.
L'ordre des jetons dans la liste ci-dessous indique leur priorité. Par exemple l'entrée MODULE sera compris comme mot clé et non comme identifiant.
Mots clés:
MODULE,SEC,END_SEC,IMPORTS, etIMPLEMENTED_BYOP : une séquence non vide des caractères suivants :
.:,%()[]{}<>|+-*/@!?^°=\~Remarque : Les marqueurs de commentaire
//,(*, et*)ont une priorité plus élevée que les opérateurs. Il ne peut y avoir aucun commentaire à l'intérieur d'un opérateur aucun commentaire ne peut être, exemple :+//+sera, selon la règle de longueur maximale, interprété comme un opérateur et non comme+suivi d'un commentaire.LIT : Un littéral CEI, tel qu'il est utilisé dans ST, exemple :
1.4,tod#12:13:14. Cela inclut les littéraux booléensTRUEetFALSE(les majuscules ou les minuscules ne sont pas pertinentes).Remarque : les littéraux non typés avec un signe négatif (
-1,-3.2) sera lu comme deux jetons, c'est-à-dire comme opérateur-suivi d'un littéral non typé. Les littéraux numériques non typés qui en résultent ne peuvent jamais être négatifs. Littéraux typés (INT#-34) sera toujours interprété comme un jeton.ID : un identifiant CEI valide (
[a-zA-Z_][a-zA-Z0-9_]*), dans lequel deux soulignements consécutifs ne sont pas autorisés. Cela inclut, contrairement à ST, également les mots-clés de ST (c'est-à-dire :FUNCTION,INT,EXTENDS, …)Point-virgule : le personnage
;
Syntaxe (analyseur)
La syntaxe de la déclaration du module est définie par la grammaire suivante. µ est une séquence vide.
{MDecl} ::= MODULE {QID} {ImplSpec} {ImportsSpec} {MBody}
{ImplSpec} ::= IMPLEMENTED_BY {QID} | µ
{ImportsSpec} ::= IMPORTS {QID} | µ
{MBody} ::= {SecList}
{SecList} ::= {Modifiers} {Sec} {SecList} | µ
{Sec} ::= SEC {QID} {SecTarget} {EntryList} END_SEC
{SecTarget} ::= OP(":") {QID} | µ
{Modifiers} ::= OP("[") {ModifierList} OP("]") | µ
{ModifierList} ::= {QID} OP(",") {ModifierList} | {QID}
{EntryList} ::= {Modifiers} {Entry} {EntryList}
{Entry} ::= {Sec} | {Def}
{Def} ::= {QID} OP(":=") {ValList} SEMICOLON |
{QID} SEMICOLON
{ValList} ::= {Val} {ValList} | {Val}
{Val} ::= ID | LIT | OP
{QID} ::= ID | ID OP(".") {QID}La liste des valeurs de définition ({ValList}) doit être complété par un point-virgule. Cela simplifie la grammaire et évite les ambiguïtés, car le point-virgule ne peut pas faire partie d'une valeur ({VAL}), sauf dans un littéral de chaîne.
L'opérateur d'affectation (:=) des définitions ({Def}) sert également à éviter les ambiguïtés ({QID}) des noms et valeurs de définition.
Types définis pour les définitions
Texte : ID.ID (nom de la liste de textes et identifiant de la liste de textes) - voir Localisation des chaînes de liste de textes
Image : ID.ID (nom du pool d'images et identifiant du pool d'images)
ID (identifiant CEI)
QID (Identifiant Qualifié) :
{QID} ::= ID | ID.IDCategoryPath ::= {StringLiteral} | {CategoryPath}Cardinalité :
[{MIN} .. {MAX}]|[ {MIN} .. INF [{MIN}, et{MAX}sont des littéraux entiers non négatifs. Si{MAX} != INF, alors{MIN} <= {MAX}doit postuler.StringLiteral : un littéral de chaîne CEI peut contenir des sauts de ligne.
StdTaskFlags ::= {StdTaskFlag} | {StdTaskFlags} StdTaskFlag ::=
NONE|CREATE_IF_MISSING|READONLYLittéral : tout littéral CEI ou QID (pour les constantes Enum)
DTBoolFlag :
µ(séquence vide) |TRUE|FALSEType d'emplacement :
SUBMODULE|REFERENCEPragmes :
[ {PragmaList} ] {PragmaList} ::= {Pragma}|{Pragma} , {PragmaList} {Pragma} ::= { ( ID|{StringLiteral}|{OP2} )+ } {OP2}: tous les opérateurs sauf{, }, [, ]et,.Chemin d'instance :
InstancePath ::= {IComp}|{IComp} . {IComp}avec{IComp} ::= ID {ArrayAccess}*et{ArrayAccess} ::= [ {IntList} ]et{IntList} ::= Int|Int , {IntList}TaskRef : Standard_Task. (
Low|Medium|High) |Custom_Task.ID
Chemins d'instance
À certaines positions dans la déclaration du module, des chemins d'instance peuvent être définis pour adresser une variable d'un bloc fonctionnel : pour les paramètres, les emplacements, les E/S, les tableaux avec une taille variable et les références d'instance.
Un chemin d'instance est défini comme une séquence non vide de composants, séparés par des points : C1.C2…CN. Un composant doit être soit un identifiant CEI, soit un composant suivi d'une expression d'index [i1, …, iN], où i1 à iN sont des valeurs entières.
Les chemins d'instance sont toujours relatifs au bloc fonctionnel qui implémente la logique du module. Le premier composant du chemin d'instance est un membre (VAR_INPUT ou VAR_OUTPUT, selon le cas d'utilisation) du bloc fonctionnel. Si le chemin d'instance comporte des composants supplémentaires, ces composants s'adressent à la variable au sein du membre. Dans le cas contraire, le membre lui-même est adressé. Les chemins d'instance peuvent être limités aux variables d'entrée ou de sortie (exemple : pour les E/S). Ces restrictions ne sont pas valables pour les structures. Ces types de chemins d'instance sont appelés chemins d'instance d'entrée et chemins d'instance de sortie.
Localisation des chaînes de liste de textes
Les textes des modules (exemple : description du module, nom, description du paramètre) peuvent être affichés dans différentes langues. Ces textes sont gérés dans des listes de textes.
Le nom de la langue est de format
<LanguageCode>[-<Country/Region>](exemple:en-US,de-DE).<LanguageCode>est le nom de la langue selon la norme ISO 639-1 (exemple :deouen).<Country/Region>est un code de pays selon la norme ISO 3166.Lors de la récupération d'une entrée de liste de textes, le système recherche d'abord le nom complet de la langue. Si rien n'est trouvé, il recherche le
<LanguageCode>. Si cette recherche échoue également, le texte par défaut sera utilisé.
Langue | Nom de la langue |
|---|---|
Chinois | zh-CHS |
Anglais | fr-US |
Français | F RFR |
Allemand | de-DE |
italien | ça ça |
Japonais | ja-JP |
Portugais | pt-PT |
russe | ru-RU |
Espagnol | es-ES |
Dérivation des déclarations de module
De la même manière que pour l'héritage orienté objet d'un bloc fonctionnel A à partir d'un bloc fonctionnel B (« EXTENDS »), il est possible de dériver des déclarations de module en utilisant IMPORTS mot clé. UPDATE et HIDE les modificateurs sont traités spécialement.
Le nom du module importé doit être spécifié avec un espace de noms si ce module est défini dans une autre bibliothèque.
Les importations cycliques ne sont pas autorisées, en particulier un module ne doit pas s'importer lui-même. (Exemple d'import cyclique : le module M_1 importe le module M_2, M_2 importe M_3, …, M_N importe à nouveau M_1.)
Un module dérivé peut être défini sans le
IMPLEMENTED_BYdirectif. Dans ce cas, le bloc fonction du module de base sera utilisé.Si un module dérivé spécifie un bloc fonction (en utilisant
MPLEMENTED_BY), ce bloc fonction doit dériver du bloc fonction du module de base ou doit lui être identique.Un module dérivé hérite de toutes les sections du module de base. Il peut ajouter de nouvelles sections ou modifier des sections existantes.
Une section peut être modifiée dans le module dérivé en utilisant le même nom et la même cible étendue avec le modificateur
UPDATE. Dans ce cas, ses entrées sont modifiées. Toutes les définitions manquantes de la section dans le module dérivé seront reprises du module de base.Le modificateur
UPDATEetHIDEne peut être utilisé que si la section correspondante (nom et cible) est définie dans le module de base. A l'inverse, une section définie dans le module de base ne peut être utilisée dans le module dérivé que si elle possède l'attributHIDEouUPDATEmodificateur. S'il n'y a que leHIDEmodificateur dans la section et nonUPDATE, alors aucune définition n'est autorisée.Certaines entrées doivent être modifiées dans le module dérivé (exemple : la description).
MODULE MBase IMPLEMENTED_BY FBBase
SEC MetaData
DESC := TL.Desc_Base ;
END_SEC
SEC Parameters
SEC Param : paramxIn
Variable := xIn ;
Name := TL.Param1_Name ;
Desc := TL.Param1_Desc ;
END_SEC
END_SEC
MODULE MDerived IMPORTS MBase
[UPDATE] SEC MetaData
DESC := TL.Desc_Derived ;
END_SEC
[UPDATE] SEC Parameters
[UPDATE,HIDE] SEC Param : paramIn
Variable := xIn ;
DEFAULT := TRUE ;
END_SEC
END_SECDans l'exemple ci-dessus, le paramètre paramIn du module MBase est caché dans le module dérivé MDerived (en utilisant le HIDE modificateur), et en même temps une nouvelle valeur par défaut (TRUE) est défini.
Notes sur l'ordre des sections et des définitions
L'ordre des sections juste après l'en-tête du module n'est pas pertinent. Au sein des sections, l'ordre peut être très important. Par exemple, l'ordre des déclarations d'emplacements définit l'ordre des modules dans l'arborescence des modules.
L’ordre des définitions n’a toujours pas d’importance.
Les sections des modules de base sont toujours définies avant les sections du module lui-même.
Si une section du module de base est modifiée à l'aide de
UPDATEouHIDE, son ordre n'est pas affecté.Il n'est pas possible pour un module dérivé de modifier l'ordre tel que défini dans le module de base.
Auto-complétion et « liste des composants »
Lorsque vous commencez à taper dans l'éditeur de module, toutes les définitions de section disponibles/possibles sont affichées dans un menu « Liste des composants ». Seules les sections et définitions pertinentes pour la position actuelle sont affichées. Même si certaines entrées de sous-section portent le même nom que les entrées de sous-section d'autres sections, il essaiera d'afficher uniquement les définitions de section correspondantes.
Si Retour est enfoncé après avoir terminé la première ligne d'une section, la section sera alors complétée avec toutes les définitions/sections nécessaires et le END_SEC .
Après les définitions des variables, les variables d'entrée/sortie sont présentées par des définitions de « composants de liste ». Les indicateurs ou valeurs prédéfinies sont également présentés dans une sélection de « composants de liste », qui montre les indicateurs/valeurs possibles.
Après les définitions, qui utilisent des entrées de liste de texte ou des entrées de pool d'images (exemple : la plupart du temps Desc :=), un menu « composants de liste » comprenant toutes les listes de textes ou pools d'images disponibles et visibles et leurs entrées est présenté.
En appuyant F2, le support de saisie correspondant peut être ouvert.