CODESYS String Libraries
Introducción
Las bibliotecas del CODESYS String Libraries el paquete se puede usar para procesar cadenas codificadas en UTF-8. La base es la IString interfaz desde el String Segments biblioteca. Con esta interfaz, las cadenas se pueden pasar a las funciones respectivas por referencia. Por ejemplo, para crear un IString instancia, el GSB.UTF8String bloque de funciones del Generic String Base se proporciona una biblioteca.
| Funciones básicas para | |
| Gestión eficiente de segmentos de cadena codificados en UTF-8 | |
| Conversión de cadenas de diferente codificación hacia/desde UTF-8 | |
| Funciones para procesar cadenas codificadas en UTF-8 siguiendo el ejemplo de la biblioteca estándar convencional. | |
| Funciones para procesar categorías de caracteres Unicode. | Documentación de la biblioteca de funciones de soporte de Unicode |
| Función básica para gestionar áreas de memoria codificadas en UTF-16 | Documentación de la biblioteca de soporte de codificación UTF-16 |
| Función básica para gestionar áreas de memoria codificadas en UTF-8 | Documentación de la biblioteca de funciones de soporte de codificación UTF-8 |
| Bloques de funciones para procesar cadenas codificadas en UTF-8 que gestionan su memoria de forma estática mediante | Documentación de la biblioteca de funciones básicas de cadenas genéricas |
Ventajas de las nuevas bibliotecas de cadenas
Importante
Las nuevas bibliotecas de cadenas no sustituyen a las antiguas funciones de cadenas conocidas del Standard y Standard64 bibliotecas. Sin embargo, recomendamos usar las nuevas bibliotecas de cadenas para proyectos nuevos.
Las nuevas bibliotecas de cadenas también pueden gestionar cadenas grandes de forma eficiente. La longitud de las cadenas es casi ilimitada. Por esta razón, las bibliotecas también son adecuadas para editar archivos de texto y contenido web de gran tamaño.
UTF-8 es una codificación que puede representar la gama completa de caracteres según UNICODE.
UTF-8 se usa ampliamente en Internet y es recomendado por el World Wide Web Consortium (W3C).
UTF-8 es compatible con los sistemas antiguos debido a su compatibilidad con ASCII.
UTF-8 proporciona un alto nivel de interoperabilidad.
UTF-8 funciona para optimizar la memoria.
Las nuevas bibliotecas de cadenas le permiten consultar una cadena previamente definida mediante los métodos correspondientes, tal como la conoce en otros lenguajes de alto nivel.
Len()udiStringLen := myString.Len(); if udiStringLen = 22 THEN ...
A partir de CODESYS 3.5.18.0, puede configurar el compilador para que interprete el contenido de las variables de tipo STRING como codificación UTF-8. Seleccionas Codificación UTF-8 para STRING opción en el Configuración del proyecto en el Opciones de compilación categoría.
Si no quieres tratar a todos STRING las variables de un proyecto están codificadas en UTF-8, debe desactivar esta opción. Después de eso, puede aplicar la codificación UTF-8 a STRING escriba caso por caso.
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';Gracias a las capacidades de codificación UTF-8, no es necesario utilizar el WSTRING escriba datos en CODESYS para usar un conjunto de caracteres extendido. codificación UCS-2 WSTRING se basa en, puede requerir más memoria que una codificación UTF-8, según la aplicación. La codificación UCS-2 siempre usa WORD por carácter y solo puede representar los caracteres U+0000 para U+D800 y U+DFFF para U+FFFD. La codificación UTF-8 requiere entre uno y cuatro bytes por carácter. Como resultado, se pueden procesar todos los caracteres Unicode
Con la codificación UTF-8, si intentas obtener un carácter específico usando un índice específico, esto generará resultados inesperados debido a la longitud variable.
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
byValue := sValue[13]; // The 'u' is NOT the 13th character in the string
xOk := byValue <> 16#75;Debe determinar el índice de un carácter iterando la cadena.
VAR
{attribute 'monitoring_encoding' := 'UTF-8'}
sValue : STRING(140) := UTF8#'Ðα ṧтℯ♄ ḯḉℌ ηuη, i¢ℌ αямℯґ 𝕋øґ‼ Ṳᾔⅾ ♭ḯη $☺ ḱℓυℊ αł$ ωⅈ℮ ẕυ√◎ґ';
fbsValue : STR.UTF8Literal := (psValue:=ADR(sValue));
fbRange : STR.Range := (itfString:=fbsValue);
diRune : STR.RUNE;
udiIndex, udiLength : UDINT;
xOk : BOOL;
END_VAR
WHILE (diRune := fbRange.GetNextRune(udiLength=>udiLength)) <> 0 DO
IF diRune = 16#75 (* 'u' *) THEN
EXIT;
END_IF
udiIndex := udiIndex + udiLength;
END_WHILE
xOk := sValue[udiIndex] = 16#75 (* 'u' *);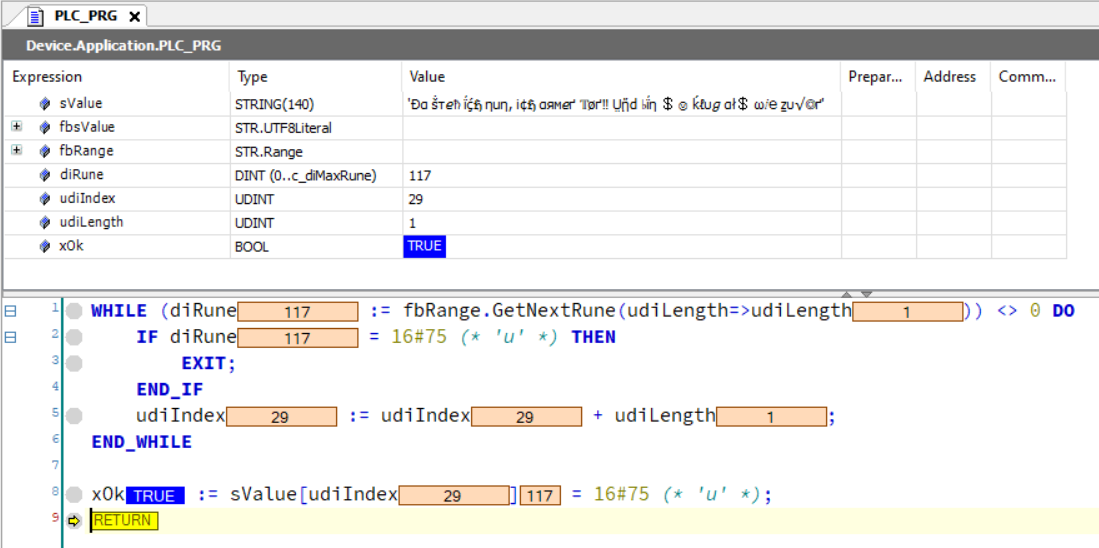
Desventajas de lo establecido STRING funciones
En el anteriormente establecido STRING funciones de la biblioteca estándar, los parámetros de tipo STRING se copian cuando se pasan a las funciones. El valor devuelto también se copia a una variable con la asignación.
VAR
sValue : STRING;
END_VAR
sValue := CONCAT(CONCAT(CONCAT('Da steh ich nun,', ' ich armer Tor!'), ' Und bin so'), ' klug als wie zu vor');
// -> Copy, LEN -> Copy, LEN -> Copy, LEN -> Copy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LEN
// -> 2xCopy, LENAntes de procesar los parámetros de tipo STRING en las funciones respectivas, sus longitudes a menudo tienen que determinarse mediante iteración hasta el carácter nulo final. En el caso de cadenas más largas, estas operaciones de copia e iteración aumentan el tiempo de procesamiento de la aplicación. La longitud de las cadenas está limitada a 255 caracteres para la aplicación de estas funciones
Uso del IString interfaz
El STR.IString La interfaz se introdujo para pasar la estructura de datos que administra la información sobre una cadena por referencia. Esta es una diferencia importante con respecto a las funciones STRING establecidas anteriormente, que no implementan la STR.IString interfaz.
Además, el tamaño de una cadena (la memoria respectiva para los caracteres codificados en UTF-8) puede estar en el rango numérico. UDINT 4 ≦ udiSize ≦ 16#FFFF_FF00).
Referencia al segmento de memoria respectivo
Capacidad actual (→
GetSegment)Longitud (→
Len) en bytesNúmero de caracteres (→
RuneCount)
STR.IStringVAR
itfString : STR.IString;
udiLength, udiSize, udiRuneCount : UDINT;
pbySegment : POINTER TO BYTE;
xValid : BOOL;
END_VAR
udiLength := itfString.Len(); // Current length in byte
pbySegment := itfString.GetSegment(udiSize=>udiSize); // Address first byte, capacity of the segment in bytes
udiRuneCount := STR.RuneCount(itfString); // Current number of "characters" in the segment
xValid := itfString.IsValid(); // Indication that a valid UTF-8 encoding is present.Correlación: «personaje» y «runa»
El término «runa» aparece en las bibliotecas y en el código fuente y significa exactamente lo mismo que «punto de código Unicode», con una adición interesante.
Las bibliotecas definen la palabra «runa» como un alias para el tipo DINT. Como resultado, el usuario puede ver claramente cuándo un valor entero representa un punto de código. Además, lo que puede imaginarse como una constante de caracteres se denomina constante rúnica
Ejemplo: El tipo y el valor de la expresión WSTRING#"⌘" es una runa con un valor entero DINT#16#2318.