Path Preprocessing and Queue Sizes
Pipelining of G-code processing
When G-code is read from a file, it is often impractical to read and process the entire file before starting machining. For some applications, G-code files can have a few hundred thousand or even millions of lines. Reading all at once would take a long time and also require a lot of memory.
Instead, the G-code is read line by line, but only a small fraction (a few hundred lines) is kept in memory at each point in time. This part is kept in queues, i.e. in data structures which work according to the "first in, first out" principle: The producing function block adds elements to the queue. The consuming function block reads and removes elements in the same order they were inserted.
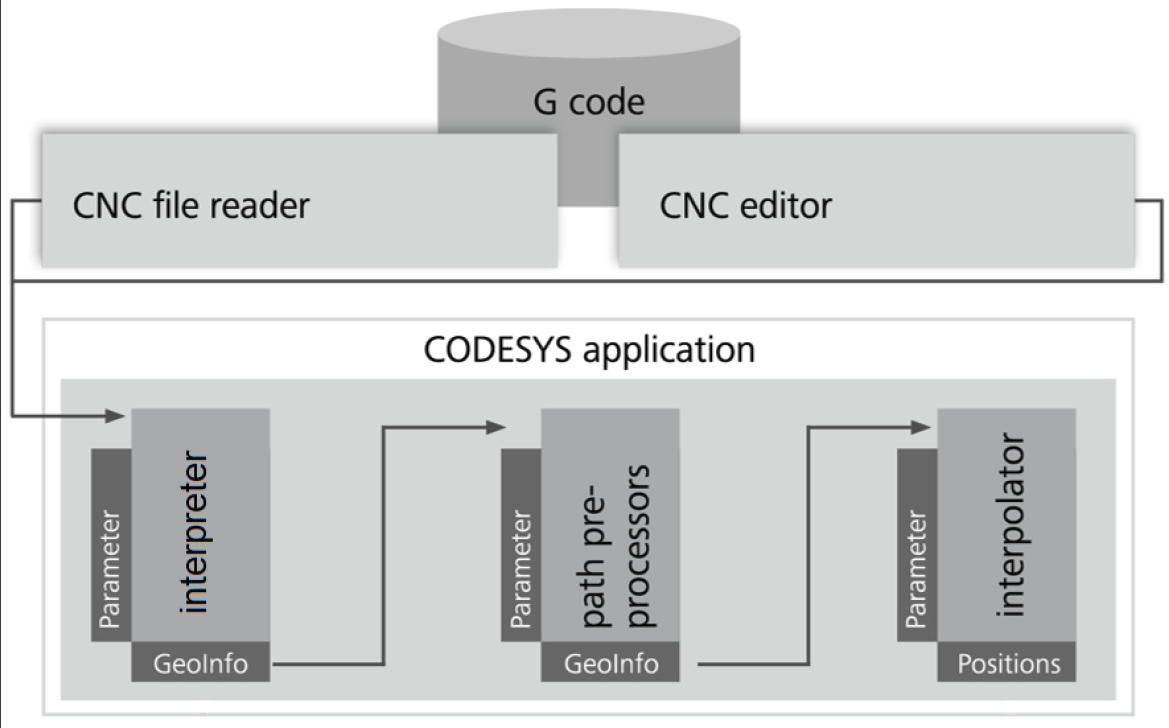
The diagram shows the flow of the G-code through the system. First, G-code is read from a file, then converted into so called GeoInfo elements by the interpreter. These elements are processed by the path preprocessing function blocks and finally interpolated. The parts marked by "GeoInfo" represent the queues. If more than one path preprocessor (such as SMC_SmoothPath, SMC_ToolRadiusCorr, or SMC_AvoidLoop) is used, then they are also connected by queues.
Recommended queue sizes
As a rule of thumb, for most queues a size of 16 elements is suitable. The last queue before the SMC_Interpolator function block (that is usually the queue of the path preprocessing function block before SMC_CheckVelocities) should have a higher queue size – 100 elements is a good starting point for most applications.
Latency of processing: the larger the queues, the longer it will take to fill them up initially. The
SMC_Interpolatorfunction block waits until the last queue is filled before starting with interpolation. For the latency, the total queue size (sum of all queue sizes) is relevant.Lookahead of the interpolator: the size of the last queue before the
SMC_Interpolatordetermines the lookahead of the interpolation. When computing a trajectory, the interpolator can only plan until the end of the lookahead. If the lookahead is too small, then the interpolator might not be able to reach the full path velocity. Depending on the path velocity and length of the elements, 100 elements is a good starting point, but for high velocities and/or short elements, a larger queue size might be necessary.Effect on particular function blocks: Function blocks such as
SMC_AvoidLooporSMC_SmoothMergerequire a certain size of the incoming queue to work effectively. For example, to detect a loop in the G-Code, this loop must fit into the queue beforeSMC_AvoidLoop. Check the documentation of the function blocks in your path processing pipeline for details.
Calling the processing function blocks
As mentioned above, interpolation starts only after all queues are filled up. This causes an initial latency when starting machining. Besides reducing the total queue size, there is an additional way to reduce this latency.
The path preprocessing function blocks are usually called in a cyclic background task, as shown in the examples such as CNC Example 03: Performing Path Preprocessing Online. To reduce latency, the program calling SMC_ReadNCFile2, SMC_NCInterpreter, and the path preprocessors can be called in a loop. Depending on the application and task priorities, it may be sufficient to execute the program multiple times per task call (e.g. 100 times) or to terminate the loop after a certain time span (e.g. 5 ms).