Bahnvorverarbeitung und Queue-Größen
Stückweise Abarbeitung von G-Code
Es ist oft nicht sinnvoll, G-Code Dateien komplett einzulesen, bevor mit der Abarbeitung begonnen wird. Für manche Anwendungen können G-Code-Dateien Hunderttausende oder sogar Millionen von Zeilen umfassen, so dass das komplette Einlesen viel Zeit und Speicher benötigen würde.
Stattdessen wird der G-Code eingelesen und jeweils nur ein kleiner Teil (einige hundert Zeilen) gleichzeitig im Speicher gehalten. Dieser Teil wird in Queues gehalten, also in Datenstrukturen, die nach dem "First in, first out"-Prinzip funktionieren: Der Baustein, der die Queue befüllt, hängt Elemente in die Queue ein. Der Baustein, der aus der Queue liest, entnimmt Elemente in derselben Reihenfolge, in der sie eingefügt wurden.
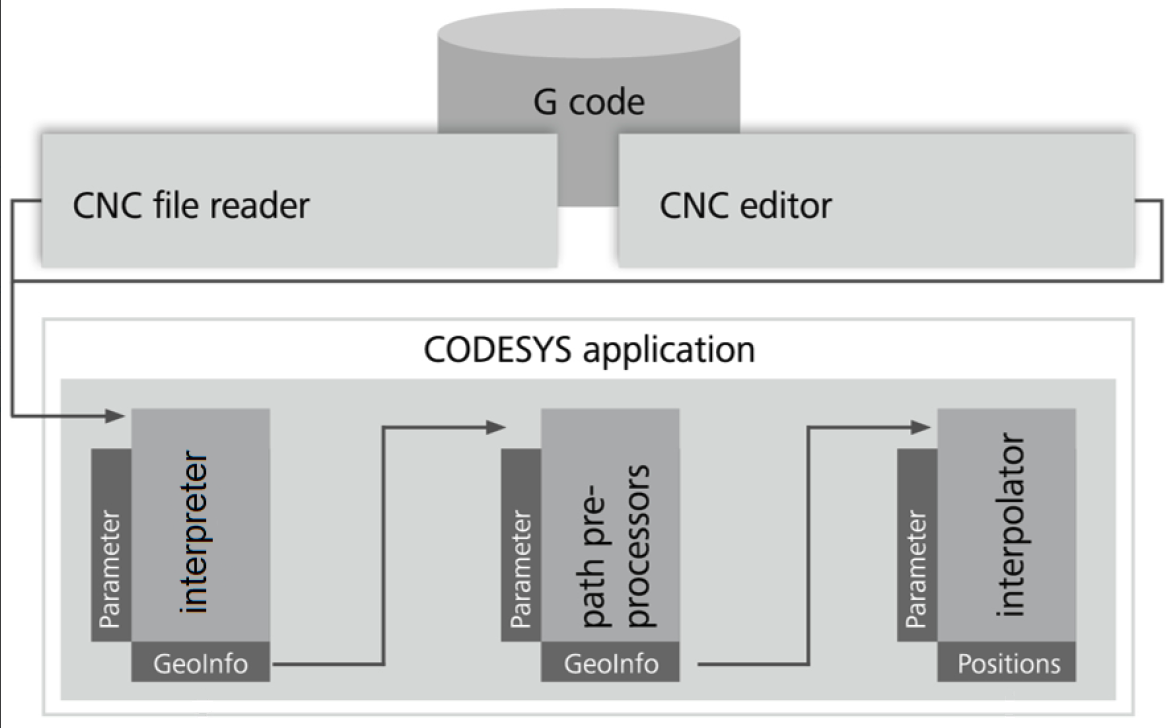
Das Diagramm veranschaulicht den Datenfluss des G-Codes. Zuerst wird der G-Code aus einer Datei eingelesen, dann im Interpreter in sogenannte GeoInfo-Elemente umgewandelt, dann von Bahnvorverarbeitungsbausteinen bearbeitet und schließlich interpoliert. Die mit "GeoInfo" gekennzeichneten Rechtecke stehen jeweils für eine Queue. Wenn es mehrere Bahnvorverarbeitungsbausteine gibt (beispielsweise SMC_SmoothPath, SMC_ToolRadiusCorr oder SMC_AvoidLoop), dann sind sie jeweils über eine eigene Queue verbunden.
Empfohlene Queue-Größen
Als Richtwert sollten die meisten Queues eine Größe von 16 Elementen haben. Die letzte Queue vor dem Baustein SMC_Interpolator (das ist in der Regel die Queue des Bahnvorverarbeitungsbausteins vor SMC_CheckVelocities) sollte eine Größe von 100 Elementen haben.
Latenz beim Einlesen: Je größer die Queues sind, desto länger dauert es, sie initial zu füllen. Der Baustein
SMC_Interpolatorwartet mit dem Start der Interpolation, bis die letzte Queue komplett gefüllt ist. Für die Latenz zählt die Summe aller Queue-Größen.Vorausschau des Interpolators: Die Vorausschau des Interpolators wird durch die letzte Queue vor dem Baustein
SMC_Interpolatorbestimmt. Wenn dieser die Trajektorie berechnet, kann er nur bis zum Ende der Vorausschau planen. Ist die Vorausschau zu klein, dann erreicht er unter Umständen nicht die volle Vorschubgeschwindigkeit. Abhängig von der Vorschubgeschwindigkeit und der Länge der Bahnelemente kann es sein, dass die empfohlene Größe von 100 Elementen zu klein ist.Auswirkung auf bestimmte Funktionsbausteine: Funktionsbausteine wie
SMC_AvoidLoopoderSMC_SmoothMergebenötigen eine bestimmte Größe der Queue, aus der sie lesen, um gute Ergebnisse zu erzielen. DurchSMC_AvoidLoopwerden zum Beispiel nur Schleifen im G-Code erkannt, die komplett in die Queue passen. In der Dokumentation der Vorverarbeitungsbausteine finden sich nähere Informationen.
Aufruf der Vorverarbeitung
Wie oben erwähnt startet die Interpolation erst, wenn alle Queues initial gefüllt sind. Dies verursacht eine Latenz zwischen dem Start der Vorverarbeitung und dem Start der Interpolation und damit der Abarbeitung durch die Maschine. Um diese Latenz zu reduzieren gibt es neben der Verkleinerung der Queues noch eine weitere Möglichkeit.
Die Bahnvorverarbeitungsbausteine werden üblicherweise in einer zyklischen Hintergrundtask aufgerufen, wie in diesem Beispiel: CNC-Beispiel 03: Bahnvorverarbeitung online durchführen. Zur Verringerung der Latenz kann das Programm, das SMC_ReadNCFile2, SMC_NCInterpreter und die Bahnvorverarbeitungsbausteine enthält, in einer Schleife aufgerufen werden. Je nach Applikation und Task-Prioritäten kann es ausreichend sein, das Programm pro Task-Aufruf mehrfach ausführen zu lassen (beispielsweise 100 mal) oder die Schleife nach einer bestimmten Zeitspanne (beispielsweise 5 ms) abzubrechen.